
Eksplozja AI?
#75

Cześć i czołem dobry człowieku! 👋
Eksplozja AI?
I. Pale Blue Dot

14 lutego 1990 roku sonda Voyager 1, oddalona od Ziemi o sześć miliardów kilometrów, obróciła się na chwilę i zrobiła zdjęcie. Na fotografii widać ciemność kosmosu i maleńką, ledwo zauważalną kropkę — nasz dom, zawieszony w promieniu słońca jak pyłek w świetle. Carl Sagan patrząc na to zdjęcie napisał słowa, które nie pozwalają mi spokojnie przejść obok nocnego nieba:
„Spójrzcie jeszcze raz na tę kropkę. To tutaj. To nasz dom. To my. Wszyscy, których kochacie, wszyscy, których znacie, wszyscy, o których kiedykolwiek słyszeliście, każda istota ludzka, jaka kiedykolwiek żyła — przeżyła swoje życie właśnie na niej. (...) Nasza pycha, nasze urojone przekonanie o własnym znaczeniu, mrzonka o naszej uprzywilejowanej pozycji we wszechświecie — wszystko to blednie w obliczu tej bladej, błękitnej kropki” — Carl Sagan, Pale Blue Dot (1994)
Piszę o tym nie bez powodu. Sagan nauczył mnie dwóch rzeczy: pokory wobec ogromu tego, czego nie wiemy — i fascynacji tym, że w ogóle próbujemy to zrozumieć. Obie te lekcje są potrzebne, żeby uczciwie napisać o tym, co dzieje się ze sztuczną inteligencją w lutym 2026 roku.
Analogia, która nie chce się zestarzeć
Przypomnij sobie luty 2020 roku. Jeśli uważnie śledziłeś wiadomości, mogłeś zauważyć, że kilka osób mówi o wirusie rozprzestrzeniającym się gdzieś w Azji. Ale większość z nas nie słuchała. Giełda rosła, dzieci chodziły do szkoły, ściskaliśmy sobie dłonie na spotkaniach i planowaliśmy wakacje. Gdyby ktoś powiedział ci wtedy, że za kilka tygodni świat się zatrzyma — pomyślałbyś, że spędził za dużo czasu w dziwnym zakątku internetu.
Matt Shumer, przedsiębiorca, który został wyróżniony w 2024 roku w Forbes 30 Under 30, od sześciu lat buduje firmy w branży AI (OthersideAI i HyperWrite), uważa, że przeżywamy właśnie tę samą fazę — fazę „to jest przesadzone” — tyle że tym razem stawka jest nieporównanie wyższa.
„Ciągle podaję im grzeczną wersję. Wersję na przyjęcie koktajlowe. Bo wersja szczera brzmi, jakbym postradał zmysły.”
Shumer pisze otwarcie, że przepaść między tym, co mówi ludziom przy kolacji, a tym, co naprawdę się dzieje, stała się nie do utrzymania. Przez lata dawał bliskim wersję uprzejmą, dyplomatyczną, bo wersja szczera brzmiała jak szaleństwo. Ale dalsze milczenie — jak twierdzi — stało się nieodpowiedzialne.
5 lutego 2026 — punkt zwrotny?
Punktem zwrotnym, przynajmniej dla ludzi pracujących w technologii, był 5 lutego 2026 roku. Tego dnia dwa wiodące laboratoria AI — OpenAI i Anthropic — opublikowały jednocześnie nowe modele: GPT-5.3 Codex i Opus 4.6. Shumer opisuje to jak moment, w którym zdajesz sobie sprawę, że woda, która cały czas była wokół ciebie, sięga ci już do klatki piersiowej.
„Nie jestem już potrzebny do właściwej technicznej pracy w mojej firmie. Opisuję, co chcę zbudować, zwykłym językiem — i to po prostu... powstaje. Nie szkic do poprawki. Gotowy produkt.”
Jeszcze kilka miesięcy wcześniej Shumer prowadził z AI coś w rodzaju dialogu — naprowadzał, korygował, edytował. Teraz opisuje wynik, odchodzi od komputera na cztery godziny i wraca do gotowego produktu. Ale nie sama jakość wykonania zszokowała go najbardziej. To było coś, co nazwał osądem — trudnym do wytłumaczenia wyczuciem, co jest właściwą decyzją, nie tylko technicznie poprawną. Coś, o czym ludzie zawsze mówili, że AI nigdy tego mieć nie będzie.
Szczególnie uderzający jest jeden fragment dokumentacji technicznej GPT-5.3 Codex. Inżynierowie z OpenAI napisali wprost:
„GPT-5.3-Codex to nasz pierwszy model, który odegrał kluczową rolę w tworzeniu samego siebie. Zespół Codex wykorzystywał wczesne wersje modelu do debugowania własnego procesu treningowego, zarządzania wdrożeniem i analizy wyników testów.”
AI pomogło zbudować samo siebie. To nie jest prognoza — to opis tego, co już się wydarzyło. Dario Amodei, dyrektor generalny Anthropic, mówi, że AI pisze „dużą część kodu” w jego firmie, a sprzężenie zwrotne między obecną a następną generacją AI „nabiera rozpędu z miesiąca na miesiąc”. Badacze nazywają to eksplozją inteligencji. A ci, którzy wiedzą najlepiej — bo to budują — uważają, że ten proces już się rozpoczął.
Dane METR — podwajanie złożoności zadań
Organizacja o nazwie METR mierzy za pomocą twardych danych to, o czym Shumer mówi anegdotycznie. METR śledzi złożoność zadań (mierzoną czasem potrzebnym ludzkiemu ekspertowi), które model AI jest w stanie zrealizować samodzielnie, od początku do końca, bez ludzkiej pomocy.
Dwa lata temu odpowiedź brzmiała: około dziesięciu minut. Potem godzina. Potem kilka godzin. Pomiar — Claude Opus 4.5 z końca 2025 — wykazał, że AI kończy zadania, na które ludzki ekspert potrzebuje prawie pięciu godzin. Dla modelu GPT 5.2 pomiar wynosi już aż ponad 6 godzin. Tempo podwajania wynosi około siedmiu miesięcy, a nowsze dane sugerują przyspieszenie do czterech.
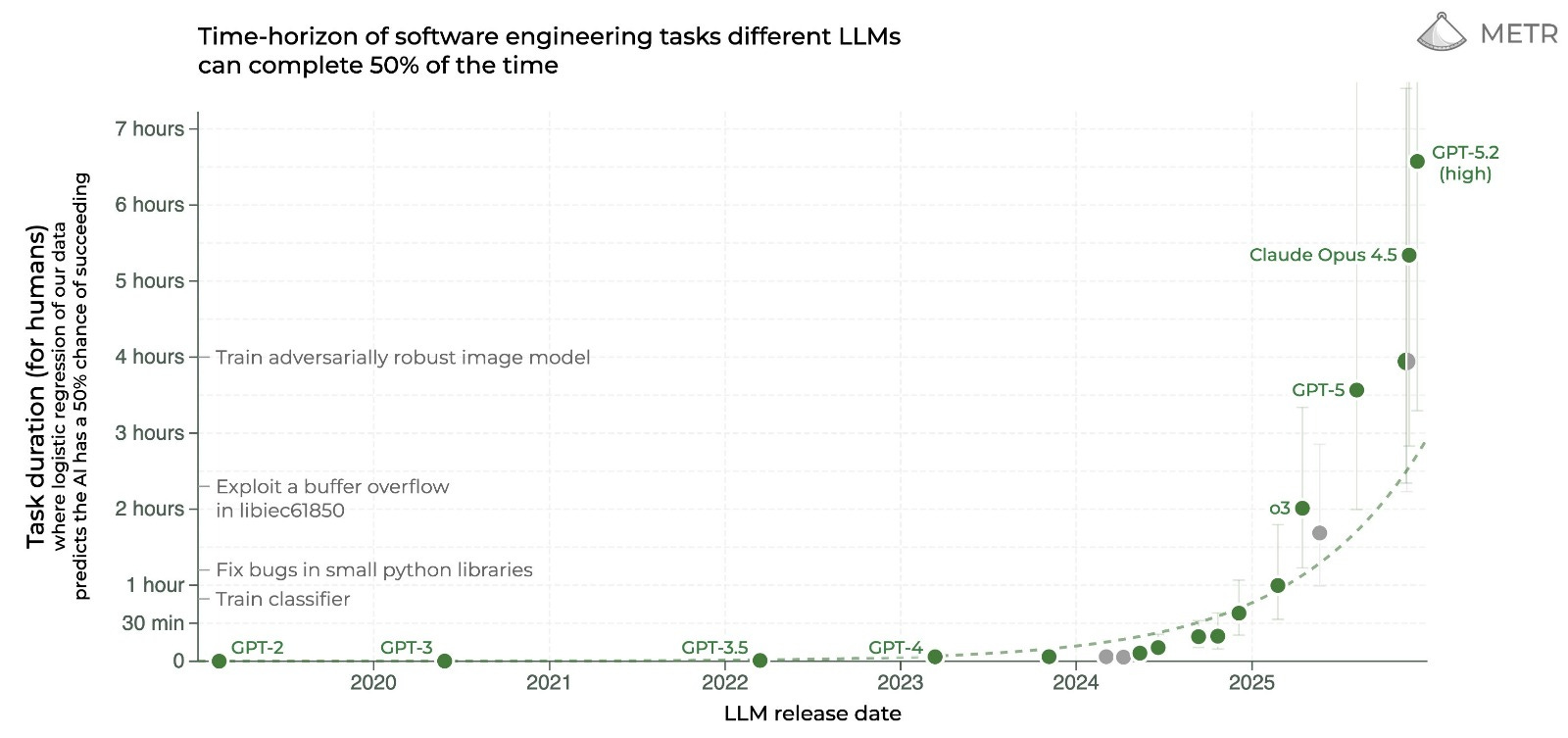
A te pomiary nie obejmują jeszcze modeli z 5 lutego 2026.
Stukrotna rewolucja przemysłowa
Demis Hassabis, dyrektor Google DeepMind i laureat Nagrody Nobla, mówi o tym samym zjawisku z perspektywy kogoś, kto pracuje nad AI od ćwierć wieku. W wywiadzie dla Bloomberga w Davos Hassabis porównał nadchodzącą transformację do rewolucji przemysłowej — ale pomnożonej razy sto:
„To będzie dziesięć razy większe i dziesięć razy szybsze. Rewolucja przemysłowa — pomnożona przez sto.”
Hassabis idzie dalej. Mówi o świecie po AGI — sztucznej ogólnej inteligencji — jako o świecie postniedoboru, w którym za pomocą AI rozwiążemy „fundamentalne supły problemów”: energię, materiały, choroby. Jeśli z pomocą AI uda się opanować fuzję jądrową, stworzyć nowe materiały i nadprzewodniki w temperaturze pokojowej — to pięć do dziesięciu lat po osiągnięciu AGI ludzkość znajdzie się w „radykalnie obfitym świecie”.
„Jeśli w końcowym rozrachunku uda nam się zbudować AGI — systemy na tym poziomie — to zmieni całą gospodarkę. To wykracza daleko poza kwestię miejsc pracy. Jeśli zrobimy to dobrze, możemy znaleźć się w świecie postniedoboru.”
Ale czy ta wizja nie jest zbyt piękna? Czy eksplozja, którą widzą ludzie pokroju Shumera i Hassabisa, naprawdę jest tym, czym się wydaje? Żeby odpowiedzieć na to pytanie, musimy najpierw zrozumieć, dlaczego nasze narzędzia pomiaru postępu AI mogą nas systematycznie oszukiwać.
II. Złudzenie McNamary
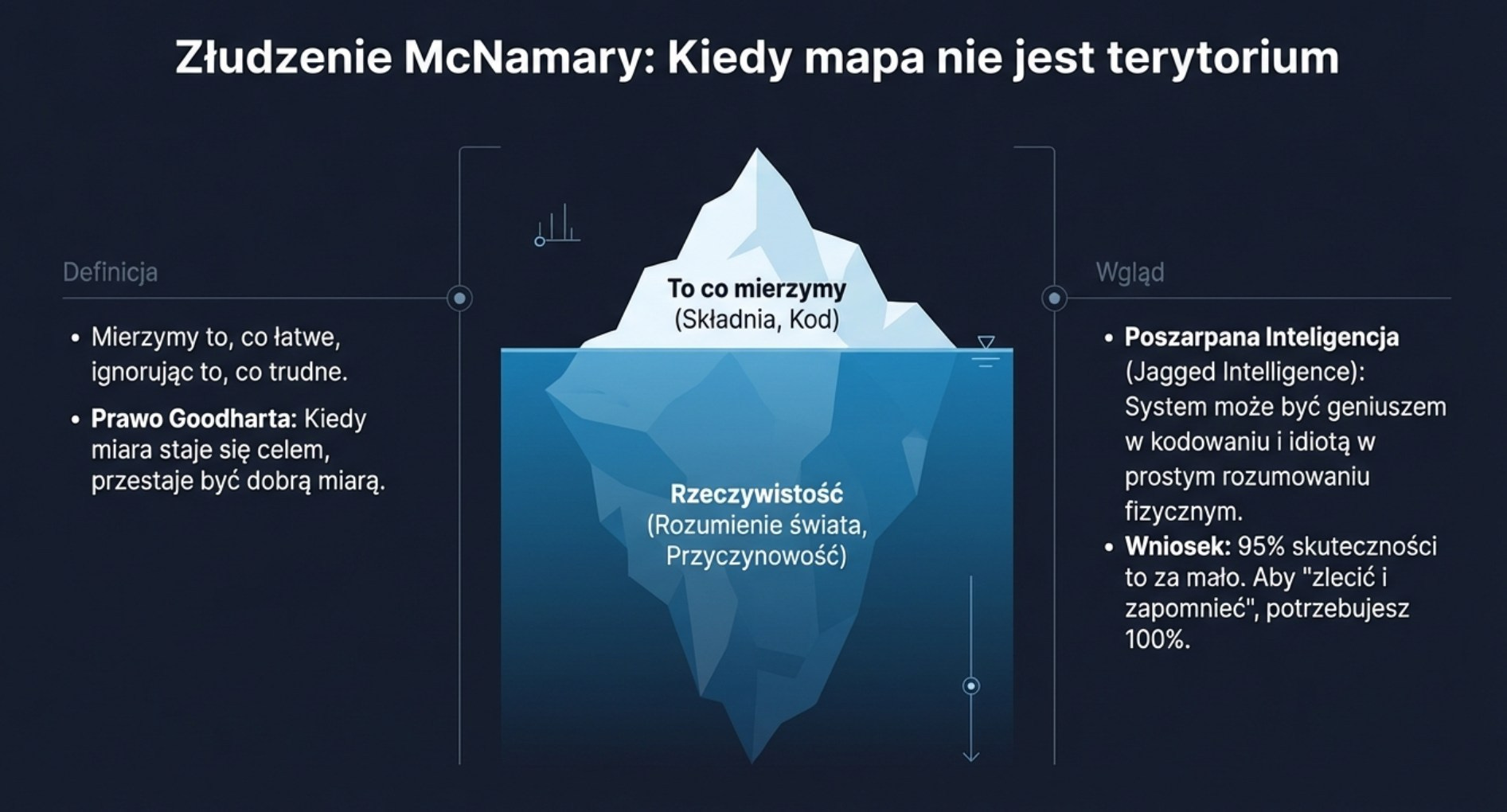
Mierz to, co mierzalne
W czasie wojny w Wietnamie sekretarz obrony USA Robert McNamara popełnił błąd, który zyskał własną nazwę w podręcznikach logiki. Złudzenie McNamary polega na skupieniu się wyłącznie na tym, co da się łatwo zmierzyć — na ilościach, statystykach, wykresach — przy jednoczesnym ignorowaniu tego, czego mierzyć się nie da, ale co decyduje o sukcesie lub porażce. McNamara mierzył liczbę zabitych Wietnamczyków i na tej podstawie wyciągał wnioski o wygrywaniu wojny. Rzeczywistość — morale, polityka, dynamika partyzancka — wymykała się jego arkuszom kalkulacyjnym.
Wielu z Was pomyśli teraz o bliźniaczym prawie Goodharta: kiedy miara staje się celem, przestaje być dobrą miarą. Oba te prawa dotyczą tego samego mechanizmu. I oba mają dziś zaskakująco dużo wspólnego z AI.
Wyobraźmy sobie AI jako ucznia, który przygotowuje się do egzaminu. Jeśli dana dziedzina jest łatwa do testowania — jeśli da się ją zmierzyć, policzyć, zweryfikować automatycznie — to znaczy, że da się w niej łatwo przeprowadzić uczenie ze wzmocnieniem (reinforcement learning). A to oznacza, że AI będzie w niej szybko rosnąć. Wykresy będą szły w górę. Nagłówki będą krzyczały o kolejnych przełomach. Dziedzina łatwa do zbenchmarkowania jest z definicji dziedziną, w której AI może się szybko poprawiać. W konsekwencji AI będzie sprawiać wrażenie postępu w każdej kolejnej domenie.
Ale co z dziedzinami, w których nie da się łatwo mierzyć sukcesu? Dziedzinami, gdzie nagrody są rzadkie, kryteria rozmyte, a granica między „dobrym” a „złym” wynikiem jest kwestią ludzkiego osądu? Te dziedziny po prostu nie generują efektownych wykresów. Nie trafiają do nagłówków. I nie są optymalizowane — bo nie ma pod co optymalizować.
Powinniśmy zatem spodziewać się, że benchmarki każdego rodzaju będą pokazywać stały wzrost wydajności. Sam fakt, że dany temat da się zbenchmarkować, oznacza, że modele AI będą się w nim poprawiać. To nie jest dowód na zbliżanie się do ogólnej inteligencji — to artefakt metody pomiaru.
Testowanie płynnej inteligencji
Istnieje jednak benchmark zaprojektowany właśnie po to, by wymknąć się tej pułapce. ARC-AGI, stworzony przez François Cholleta (twórcę biblioteki Keras i badacza w Google), nie testuje wiedzy, pamięci ani umiejętności. Testuje coś, co Chollet nazywa płynną inteligencją — zdolność do rekombinacji pojęć w locie, rozwiązywania problemów, których się wcześniej nie widziało.
Kiedy w marcu 2025 roku opublikowano ARC-AGI-2, wyniki były otrzeźwiające. Wszystkie bazowe modele językowe — GPT-4.5, Claude 3.7 Sonnet, Gemini 2 — osiągnęły 0%. Modele rozumujące (R1, o3-mini) — od 0 do 4%. Nawet o3 od OpenAI — z 76% na ARC-1 — spadł do ~4%.
Chollet wielokrotnie podkreślał, że ARC nie powstał w reakcji na duże modele językowe ani dlatego, że poprzednia wersja została „nasycona”. Planowanie kolejnych wersji — ARC-2, ARC-3, ARC-4 — było ogłoszone z wieloletnim wyprzedzeniem. Kluczowe jest też to, skąd przyszedł postęp:
„Cały postęp na ARC-1 i ARC-2 przyszedł z nowego paradygmatu: modeli z adaptacją w czasie inferencji. (...) Postęp nastąpił właśnie dlatego, że badania odeszły od tego, co ARC miał zakwestionować (statyczne uczenie głębokie), w stronę tego, co ARC miał zachęcać (adaptacja do zadania w czasie odpowiedzi).”
Niemal rok po publikacji ARC-AGI-2, nastąpił skok. 12 lutego 2026 roku pojawiły się wyniki nowego modelu Gemini 3 Pro Deepthink: 84% na ARC-AGI 2. Od listopada 2025 zaliczyliśmy ogromny wzrost w tym benchmarku z około 30% do 84%. To nie jest przyrostowa poprawa — to zmiana jakościowa, choć Chollet natychmiast ostrzega: nie mylmy nasycenia jednego benchmarku z osiągnięciem AGI.

Zapytany przez Noama Browna z OpenAI, jak szybko ARC-3 zostanie nasycone, Chollet odpowiedział: „Około roku”. I dodał:
„ARC-4 jest w przygotowaniu, premiera na początku 2027. ARC-5 też jest planowane. Ostateczna wersja to prawdopodobnie ARC-6 lub ARC-7. (...) Będziemy mogli powiedzieć, że mamy AGI, kiedy nie da się już wymyślić testu, który uwidoczni lukę w tym co łatwe dla ludzi i trudne dla modeli AI. Dziś to wciąż łatwe. Spodziewam się, że stanie się to niemal niemożliwe do 2030 roku.”
AGI w definicji Cholleta to nie przejście jednego benchmarku. To koniec samej możliwości skonstruowania testu, który ujawni różnicę między człowiekiem a AI. Benchmarking jako proces, nie jako punkt docelowy.
Poszarpana inteligencja
Demis Hassabis patrzy na ten sam problem z innej strony. W wywiadach zarówno dla Bloomberga, jak i CNBC wielokrotnie używa określenia jagged intelligence — „poszarpana inteligencja” — by opisać profil zdolności obecnych modeli:
„Są bardzo dobre w pewnych rzeczach i bardzo słabe w innych. (...) Nie wystarczy, że system radzi sobie z 95% zadania. Musi radzić sobie z całością.”
Problem jest fundamentalny. Jeśli chcesz, by agent AI samodzielnie wykonał zadanie od początku do końca — jeśli chcesz mu je „zlecić i zapomnieć” — potrzebujesz stuprocentowej niezawodności. Przy 95% masz asystenta, któremu musisz patrzeć na ręce. Przy 100% masz autonomicznego pracownika.
Hassabis dodaje w wywiadzie dla CNBC, że ta niespójność ujawnia brak kilku kluczowych zdolności. Obecne systemy nie potrafią uczyć się w sposób ciągły — są „statyczne”, zamrożone w momencie zakończenia treningu. Nie potrafią prawdziwie tworzyć — nie w sensie generowania pastiszu tego, co znane, lecz w sensie wynalezienia czegoś fundamentalnie nowego. Nie potrafią planować długoterminowo — tworzyć wieloetapowych strategii rozciągniętych na lata.
A skoro wiemy już, że benchmarki mogą kłamać o postępie, i wiemy, że profil zdolności AI jest „poszarpany” — to naturalne pytanie brzmi: czego konkretnie brakuje? Co jest tą brakującą zdolnością, która oddziela imponujący generator tekstu od prawdziwie ogólnej inteligencji?
III. Czego duże modele językowe nie potrafią
LLM-y nie potrafią skakać

W styczniu 2026 roku Tom Zahavy z Google DeepMind opublikował pracę badawczą LLMs can’t jump, która w subtelny, ale ważny sposób rysuje granice tego, co obecne architektury AI mogą — i czego nie mogą — osiągnąć. Zahavy wyróżnia trzy rodzaje wnioskowania:
Indukcja — znajdowanie wzorców w danych i ich kompresja. To jest to, w czym duże modele językowe są znakomite. To istota wstępnego treningu.
Dedukcja — wyprowadzanie wniosków z przesłanek, formalne dowodzenie. Tu modele rozumujące robią szybkie postępy.
Abdukacja — tworzenie nowych hipotez wyjaśniających, konstruowanie ram pojęciowych, które odsłaniają strukturę niewidoczną w danych.
To trzeci rodzaj — abdukacja — jest tym, czego duże modele językowe nie potrafią.
„Kluczową słabością dużych modeli językowych jest ich niezdolność do generowania nowych hipotez wyjaśniających.”
Zahavy argumentuje, że te nowe hipotezy z definicji nie znajdują się w danych treningowych. Model, który je wygeneruje, nie przewidywałby „następnego słowa” — robiłby coś fundamentalnie innego: zatrzymywałby się, konstruował w głowie całą nową architekturę wyjaśniającą, przechodził przez nią, wyprowadzał z niej aksjomaty — i dopiero potem generował odpowiedź. Tak kolosalne odejście od „przewidywania następnego tokenu” po prostu nie jest dostatecznie wynagradzane przez obecne architektury treningowe.
Dlaczego model językowy nie wymyśliłby ogólnej teorii względności
Centralną analogią tej pracy jest Einstein i ogólna teoria względności. Einstein nie kompresował dużego, zaszumionego zbioru danych, by dopasować do niego krzywą regresji. Fizyka Newtonowska działała z niesamowitą precyzją — nie było żadnego „kryzysu empirycznego”, żadnego masywnego zbioru anomalii do wyjaśnienia. Była jedna drobna anomalia — ruch orbitalny Merkurego — i poza nią wszystko zgadzało się z modelem Newtona.
„Einstein nie kompresował zaszumionego zbioru danych, by dopasować krzywą regresji. Konstruował ramy pojęciowe, które następnie w naturalny sposób odsłoniły fizyczną strukturę, której dane jeszcze nie ujawniły.”
Einstein wyobraził sobie coś, co nie istniało — windę kosmiczną, przyspieszenie w przestrzeni — i z tego eksperymentu myślowego wyprowadził równoważność grawitacji i przyspieszenia. Czerpał z percepcyjnego doświadczenia realnego świata i manipulował nim w głowie. Nie istniały żadne windy kosmiczne w 1905 roku — nie istnieją zresztą do dziś. Einstein stanął przed „ciszą w przestrzeni języka” — brakiem wcześniejszej symbolicznej reprezentacji — i mimo to skonstruował nowe ramy pojęciowe.
Co zrobiłby w tej sytuacji obecny system AI? Zahavy argumentuje, że model napędzany kompresją załatałby anomalię Merkurego dodatkowym parametrem — tak jak fizycy tamtej epoki postulowali istnienie planety Vulkan, by wyjaśnić odchylenie orbity. Zamiast rozszerzyć przestrzeń hipotez o geometrię nieeuklidesową — co zwiększa złożoność, zanim ją uprości — model wybrałby ścieżkę najmniejszego oporu.
To nie znaczy, że obecne AI nie potrafi wykonać żadnego z kroków wymaganych do takiego odkrycia. Zahavy przyznaje, że model prawdopodobnie zauważyłby „błąd w kodzie fizyki” circa 1913 — mógłby wytknąć niespójność między stałą prędkością światła w równaniach Maxwella a Newtonowskim czasem absolutnym. Ale wyprowadziłby konsekwencje zasady równoważności między grawitacją a przyspieszeniem tylko wtedy, gdyby ktoś podał mu te koncepcje jako dane wejściowe. Brakuje mu zdolności do samodzielnego skonstruowania tych koncepcji.
Modele słów kontra modele świata
Równolegle z pracą Zahavy’ego — i z zaskakująco zbieżnymi wnioskami — ukazał się esej na platformie Latent Space zatytułowany „Eksperci mają modele świata. LLM-y mają modele słów.” Tekst stawia prowokacyjną tezę: duże modele językowe mają „modele słów” — naśladują język strategii, produkują artefakty, które wyglądają ekspercko — ale nie mają „modeli świata”, czyli wewnętrznych symulacji ekosystemu agentów wzajemnie się modelujących.
Różnicę ilustruje prosty przykład. Wyobraź sobie, że jesteś trzy tygodnie w nowej pracy i potrzebujesz, by główna projektantka przejrzała Twoje projekty. Prosisz ChatGPT o szkic wiadomości na Slacku. AI pisze: „Cześć Kate, kiedy znajdziesz chwilę, czy mogłabyś zerknąć na moje pliki? Absolutnie bez pośpiechu.” Na pierwszy rzut oka wydaje się być to idealna wiadomość. Uprzejma prośba, bez naciskania.
Jednak gdy wiadomość tą przeczyta koleżanka, która zna Kate znajdzie mnóstwo zastrzeżeń: „Kate widzi ‘bez pośpiechu’ i w myślach kategoryzuje to jako nieważne. Wiadomość tonie pod piętnaścioma innymi z konkretnymi terminami. ‘Zerknij na moje pliki’ jest niejasne — nie wie, czy to dziesięć minut, czy dwie godziny. Niejasne prośby są ryzykowne. Będzie ich unikać.”
Model językowy ocenił tekst w izolacji, bez modelowania świata, w którym tekst wyląduje. Doświadczona koleżanka oceniła go jako ruch w środowisku pełnym agentów z własnymi modelami mentalnymi, odruchami selekcji priorytetów i motywacjami.
„Duże modele językowe tworzą artefakty, które wyglądają ekspercko. Nie tworzą jeszcze posunięć, które przetrwają zderzenie z ekspertem.”
Praca to poker, a AI wciąż gra w szachy
Porównajmy szachy i pokera. Szachy to gra z pełną informacją. Każdy pionek jest widoczny. Każdy legalny ruch jest znany. Nie ma ukrytego stanu, nie ma blefu. Najlepszy ruch nie zmienia się w zależności od tego, kto jest Twoim przeciwnikiem — stan planszy jest stanem planszy. AlphaGo i AlphaZero nie potrzebowały modelować ludzkiego umysłu. Potrzebowały widzieć aktualny stan i obliczać optymalną ścieżkę lepiej niż jakikolwiek człowiek.
Poker ma pozornie tę samą strukturę — ale jest jedna fundamentalna różnica: asymetria informacji. Nie znasz kart przeciwnika, on nie zna Twoich. Gra nie polega już na obliczaniu optymalnego ruchu ze wspólnego stanu. Polega na modelowaniu: kim on jest, co wie, co myśli, że Ty wiesz, i co robi z tą asymetrią.
Kiedy Meta stworzyła Pluribusa — AI, które pokonało profesjonalnych pokerzystów — klucz do sukcesu nie polegał na tym, że Pluribus „był mądrzejszy”. Pluribus był nieczytelny. Obliczał, jak zagrałby z każdą możliwą ręką, a potem balansował swoją strategię tak, by przeciwnicy nie mogli wyciągnąć z jego zachowania żadnej informacji.
Duże modele językowe są zaprojektowane dokładnie odwrotnie. Są optymalizowane na kooperatywność, uprzejmość, pomocność — cechy, które doskonale wypadają w jednorazowych ocenach ludzkich. Ale w środowisku konfrontacyjnym — w negocjacjach, w prawie, w strategii biznesowej — ta kooperatywna predyspozycja jest podatnością. Ludzki negocjator może testować, sondować, identyfikować wzorce zachowania modelu i je wykorzystywać. Model nie zauważy, że jest testowany (choć znowu w chwili pisania tego tekstu to się zmienia i nowy Opus 4.6 już to bardzo dobrze potrafi). Nie przeliczy się w trakcie interakcji. Nie dostosuje strategii do tego, że przeciwnik już go przejrzał.
To wyjaśnia, dlaczego eksperci mówią „AI mnie nie zastąpi”, a ludzie spoza branży odpowiadają „już to robi”. Patrzą na różne rzeczy. Obserwatorzy z zewnątrz oceniają artefakty — tekst, kod, grafikę. Eksperci oceniają, czy artefakt przetrwa kontakt ze środowiskiem pełnym agentów z ukrytymi motywacjami.
„To, co wygląda jak praca — to szachy. To, co jest pracą — to poker.”
„Czegoś brakuje”
I tu krąg się zamyka. Demis Hassabis wielokrotnie wraca do tego samego brakującego elementu w swoich wywiadach z początku 2026 roku:
„Czy AI potrafi samodzielnie wpaść na nową hipotezę — nie tylko rozwiązać problem, który ktoś już sformułował, co byłoby samo w sobie użyteczne i imponujące — ale czy potrafi samo wymyślić nowy koncept, nową ideę o tym, jak działa świat? Na razie te systemy tego nie potrafią. Nie mają takiej zdolności. Wygląda więc na to, że czegoś brakuje.”
Hassabis wprost wymienia brakujące elementy: prawdziwa kreatywność (nie naśladownictwo), ciągłe uczenie się, długoterminowe planowanie, modele świata — systemy, które rozumieją fizykę, przyczynowość, mechanikę rzeczywistości i mogą uruchamiać w głowie symulacje, by testować własne hipotezy. To, co najlepsi ludzcy naukowcy robią — i co obecne systemy AI robić nie potrafią.
Ale Hassabis nie jest pesymistą. Jest raczej kimś, kto widzi drogę. W tym samym wywiadzie mówi o modelach wideo (VEO) i interaktywnych (Genie) jako o „embrionalnych modelach świata” — jeśli model potrafi wygenerować realistyczną scenę fizyczną, to „w pewnym sensie rozumie coś o świecie — bo inaczej jak mógłby to wygenerować?”. Dodaje, że z jego perspektywy pytanie nie brzmi, czy duże modele językowe będą częścią systemu AGI — brzmi, czy będą jedynym komponentem:
„Jedyne pytanie, jakie sobie stawiam, to: czy to jedyny potrzebny komponent? Moim zdaniem brakuje jeszcze jednego, może dwóch przełomów — niewielkiej garstki, mniej niż pięciu.”
Modele świata. Ciągłe uczenie się. Spójność. Może coś jeszcze, ale nie dużo. Zdaniem Hassabisa jesteśmy blisko momentu, w którym te brakujące elementy zaczną wpadać na swoje miejsce. Problem w tym, że „blisko” w przypadku najważniejszej technologii w historii ludzkości może oznaczać zarówno trzy lata, jak i piętnaście.
Jedno jest pewne: obecne modele — mimo swoich spektakularnych wyników na benchmarkach, mimo zdolności do pisania kodu, planowania tras na Marsie i rozwiązywania olimpiad matematycznych — nie są jeszcze tym, za co część ludzi je bierze. Są niezwykle potężnymi maszynami do kompresji wzorców i generowania artefaktów wyglądających ekspercko. Między „wygląda jak ekspert” a „przetrwa kontakt z ekspertem” — w tej szczelinie tkwi prawdziwy problem. I rozwiązanie tego problemu jest prawdopodobnie kluczem do tego, co Hassabis nazywa superinteligencją.
IV. Spektakl bez zrozumienia
Kaczka, która przechodzi przez ściany
W poprzedniej sekcji Hassabis mówił o modelach wideo jako „embrionalnych modelach świata”. To elegancki argument. Problem w tym, że istnieje prosty test, który go podważa.
Seedance 2, model generowania wideo od ByteDance (twórców TikToka), jest jednym z najlepszych systemów tego typu na świecie (SOTA na luty 2026 roku). Sam model jest wspaniały, oto wideo wygenerowane na podstawie serialu Arcane:
Dajmy mu jednak proste zadanie: kaczka musi przejść przez labirynt od punktu startowego do czerwonego kółka w prawym dolnym rogu.
Kaczka nie nawiguje w labiryncie. Kaczka przechodzi przez ściany. Po prostu ignoruje fizyczne bariery, przecinając je w linii prostej. „Ściany” labiryntu nie istnieją w wewnętrznym modelu systemu jako przeszkody — istnieją wyłącznie jako elementy wizualne.
„Intuicyjna fizyka” kontra prawdziwa fizyka
To, co Hassabis nazywa „intuicyjną fizyką” w kontekście generatorów wideo, okazuje się czymś bliższym „intuicyjnej estetyce”. Model nauczył się, jak wygląda świat — jak zachowują się ciecze, jak spadają przedmioty, jak światło odbija się od powierzchni. I robi to wystarczająco dobrze, by „zadowolić ludzkie oko”, jak sam Hassabis przyznaje. Ale między „zadowalającym dla ludzkiego oka” a „respektującym zasady fizyki” rozciąga się przepaść, którą test labiryntu bezlitośnie odsłania.
Hassabis jest tego świadom. W wywiadzie dla Big Technology Podcast mówi wprost:
„Oczywiście to nie jest w pełni dokładne z punktu widzenia fizyki i zamierzamy to poprawić. Ale to są kroki w kierunku modelu świata.”
Kluczowe słowo to „kroki”. Hassabis nie twierdzi, że obecne generatory wideo są modelami świata. Twierdzi, że zmierzają w tym kierunku. Ale test labiryntu stawia pytanie, na które odpowiedź nie jest oczywista: czy droga od estetycznej wierności do fizycznej spójności jest krótka — wymagająca po prostu więcej danych treningowych i lepszego dostrajania — czy też jest to bariera fundamentalna, wymagająca zupełnie innej architektury?
Różnicę można zilustrować prostą analogią. Dziecko, które nigdy nie widziało labiryntu, ale rozumie pojęcie „ściana blokuje drogę”, natychmiast zrozumie, że przez ściany się nie przechodzi. Seedance 2 widział miliony filmów ze ścianami i labiryntami, ale nie rozumie pojęcia bariery — bo pojęcia nie da się wydobyć ze statystycznych wzorców pikseli. Przynajmniej nie w sposób, w jaki obecne architektury to robią.
V. Droga do superinteligencji
Project Genie
Jeśli labirynt Seedance’a 2 pokazuje, czego generatorom wideo brakuje, to Project Genie pokazuje kierunek, w którym Google DeepMind zamierza te braki wypełnić. Nie jest to różnica stopnia, lecz różnica rodzaju.
Genie 3, najnowszy model świata Google DeepMind, nie generuje filmów. Generuje interaktywne środowiska. Różnica brzmi subtelnie, ale ma kolosalne konsekwencje. Film to sekwencja klatek — model przewiduje, jak scena powinna wyglądać sekundę później. Interaktywne środowisko to coś więcej: model musi przewidzieć, jak scena zmieni się w odpowiedzi na Twoje działania. Gdy się poruszasz, Genie 3 generuje ścieżkę przed Tobą w czasie rzeczywistym. Gdy skręcasz, świat reaguje. Gdy wchodzisz w interakcję z obiektem, obiekt odpowiada.
W lutym 2026 Google udostępnił Project Genie — prototyp aplikacji opartej na Genie 3 — subskrybentom Google AI Ultra w USA. Prototyp oferuje trzy tryby interakcji: world sketching, world exploration i world remixing.
Brzmi to jak zaawansowana gra wideo — i na powierzchni nią jest. Ale pod powierzchnią kryje się coś ważniejszego. Przypomnijmy pracę Zahavy’ego z poprzedniej sekcji: Aby AI mogła dokonywać abdukcji — twórczego skoku ku nowym hipotezom — musi umieć konstruować scenariusze ‘co by było, gdyby’. Chodzi o sytuacje, które nigdy się nie wydarzyły i których próżno szukać w danych treningowych.
Genie jest narzędziem do konstruowania takich kontrafaktuałów. Jeśli model świata jest wystarczająco dokładny, możesz w nim przeprowadzić eksperyment myślowy — tak jak Einstein wyobraził sobie windę kosmiczną. Tyle że zamiast wyobrażać sobie w głowie, model może wygenerować scenariusz i obserwować jego konsekwencje. To przejście od pasywnego przetwarzania danych do aktywnej eksploracji — od „co jest w danych treningowych?” do „co mogłoby być, gdyby zmienić warunki?”. Zahavy nazywa to sterowalnością przez działanie — myśleniem poprzez działanie. I to jest, w opinii zarówno Zahavy’ego, jak i Hassabisa, brakujący element układanki.
Waymo World Model

Genie 3 nie jest abstrakcyjnym projektem badawczym zamkniętym w laboratorium. Już teraz ma konkretne, praktyczne zastosowanie — i to w dziedzinie, gdzie błąd kosztuje ludzkie życie. W lutym 2026 Waymo — dział autonomicznej jazdy Alphabet — opublikował Waymo World Model, zbudowany na fundamentach Genie 3 i zaadaptowany do specyfiki jazdy samochodowej. Model łączy szeroką wiedzę o świecie, jaką Genie 3 czerpie z ogromnego zbioru danych wideo, z precyzyjną kontrolą właściwą dla symulacji jazdy.
Dlaczego to istotne? Ponieważ autonomiczne samochody muszą radzić sobie z sytuacjami, których prawie nigdy nie spotykają na drogach — a które mogą być śmiertelne. Tornado na autostradzie. Słoń na jezdni. Dziecko wbiegające zza zaparkowanego samochodu w nietypowy sposób. Te zdarzenia są zbyt rzadkie, by zebrać wystarczającą liczbę nagrań do treningu — ale zbyt niebezpieczne, by je zignorować.
Waymo World Model rozwiązuje ten problem, symulując „niemożliwe”. Dzięki wiedzy o świecie odziedziczonej po Genie 3 model może wygenerować realistyczne scenariusze, które nigdy nie zostały zarejestrowane przez kamery Waymo.
„Symulując ‘niemożliwe’, proaktywnie przygotowujemy system Waymo na jedne z najrzadszych i najbardziej złożonych scenariuszy.”
Szczególnie interesująca jest zdolność modelu do konwersji zwykłych nagrań z kamer samochodowych na pełną symulację wielomodalną. To oznacza, że każde nagranie z drogi może stać się materiałem treningowym symulacji — a symulacja może pokazać, jak Waymo „widziałby” tę samą scenę swoimi czujnikami.
AlphaEvolve
Modele świata to jedna noga stołka. Druga to coś, co Google DeepMind nazywa AlphaEvolve — ewolucyjny agent programistyczny, który łączy kreatywność dużych modeli językowych z automatyczną oceną wyników.
Idea jest prosta, a wyniki zaskakujące. AlphaEvolve wykorzystuje zestaw modeli Gemini — szybki Gemini Flash eksploruje szeroką przestrzeń pomysłów, potężny Gemini Pro dostarcza głębokich, jakościowych sugestii. Modele proponują algorytmy w formie kodu, a automatyczne ewaluatory weryfikują, oceniają i punktują każde rozwiązanie. Najlepsze pomysły przeżywają, gorsze wymierają — czysta ewolucja, tylko że zamiast genów mutują algorytmy.
Wyniki mówią same za siebie:
W infrastrukturze Google.
AlphaEvolve odkrył heurystykę do zarządzania Borg — systemem orkiestrującym centra danych Google. Rozwiązanie działa w produkcji od ponad roku i odzyskuje średnio 0,7% globalnych zasobów obliczeniowych Google.
W projektowaniu chipów
Zaproponował modyfikację w Verilogu usuwającą zbędne bity z kluczowego obwodu arytmetycznego do mnożenia macierzy.
W treningu AIAlphaEvolve przyspieszył kluczowe jądro mnożenia macierzy w architekturze Gemini o 23%, co przełożyło się na 1% redukcji czasu treningu.
W matematyce: Znalazł nowy algorytm mnożenia macierzy 4×4 dla liczb zespolonych, używając 48 mnożeń skalarnych — poprawiając algorytm Strassena z 1969 roku. Zastosowany do ponad 50 otwartych problemów matematycznych, w 75% przypadków odtworzył najlepsze znane rozwiązania, a w 20% — poprawił je.
Wizja superinteligencji
A teraz połączmy te wątki. Bo pojedynczo — model świata, ewolucja algorytmów, robotyka — są imponującymi, ale oddzielnymi osiągnięciami. Razem tworzą coś znacznie większego: zarys planu na superinteligencję.
Praca Zahavy’ego, wywiady Hassabisa, Project Genie, AlphaEvolve — jeśli złożysz je obok siebie, wyłania się spójna architektura. Wyobraź sobie system, który internalizuje wszystkie dotychczasowe systemy Alpha — AlphaProof, AlphaFold, AlphaTensor, AlphaEvolve, WeatherNet 2 — i integruje je w jednego „naukowca AI” z Gemini i Genie w sercu.
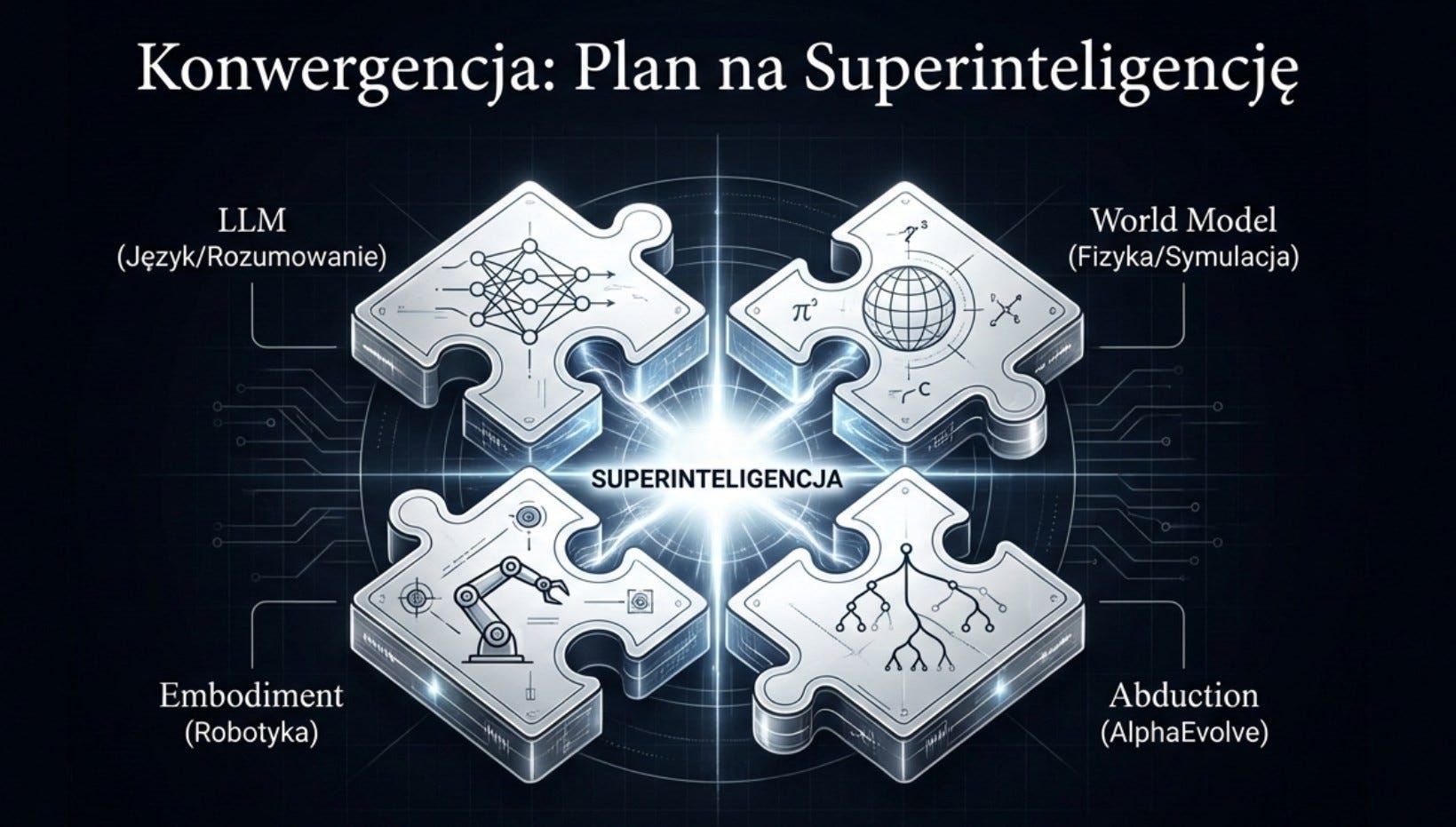
Taki system mógłby: przeskanować całą literaturę naukową na dany temat, sformułować teorię, zbudować ramy wyjaśniające, przeprowadzić hipotetyczne eksperymenty w zinternalizowanych modelach świata, wyprowadzić z nich aksjomaty — a potem, być może z pomocą robotyki, zaplanować i wykonać realne eksperymenty potwierdzające te teorie. Rzeczywistość — albo fizycznie spójne modele świata — byłyby jego pętlą zwrotną.
Hassabis mówi o tym samym, tyle że językiem biznesu i produktu. W wywiadzie dla Bloomberga opisuje konwergencję dużych modeli językowych, modeli świata i robotyki jako fundamentalny plan Google DeepMind na AGI.
Kluczowe jest tu słowo „konwergencja”. Nie chodzi o to, by modele wideo stały się lepsze, albo by AlphaEvolve odkrył więcej algorytmów, albo by roboty nauczyły się chodzić. Chodzi o to, by te wszystkie zdolności zbiegły się w jednym systemie — systemie, który widzi świat (model świata), rozumuje o nim (model językowy + rozumowanie), potrafi w nim działać (robotyka) i potrafi odkrywać nowe rzeczy (ewolucja algorytmów + abdukacja).
VI. AI w nieoczekiwanych miejscach

Claude na Marsie
8 i 10 grudnia 2025 roku komendy wysłane do łazika Perseverance na Marsie wyglądały jak coś z przyszłości. Po raz pierwszy w historii eksploracji kosmicznej trasę łazika zaplanowała sztuczna inteligencja.
Kontekst jest istotny: eksploracja Marsa to operacja prowadzona w przeszłości. Sygnał z Ziemi do łazika podróżuje około dwudziestu minut — zanim nowa instrukcja dotrze, łazik już wykonał poprzednią. Operatorzy nie mogą zarządzać każdym krokiem. Planują trasę, wysyłają ją i dopiero później widzą wyniki.
Inżynierowie JPL przetestowali, czy Claude od Anthropic potrafi wykonać tę pracę. Przygotowali środowisko w Claude Code, dostarczyli modelowi dane i doświadczenie zgromadzone przez lata kierowania łazikiem, i zlecili mu planowanie. Claude użył swoich zdolności wizyjnych do analizy zdjęć orbitalnych, pisał komendy w Rover Markup Language i łączył dziesięciometrowe segmenty w trasę, wielokrotnie ją poprawiając, krytykując własną pracę i sugerując korekty.
Wynik: około czterystu metrów — jedno okrążenie bieżni lekkoatletycznej — przez pole skalne na marsjańskiej powierzchni. Gdy inżynierowie JPL przejrzeli plany Claude’a, potrzebne były jedynie drobne poprawki.
„Inżynierowie szacują, że wykorzystanie Claude’a w ten sposób skróci czas planowania tras o połowę i uczyni je bardziej spójnymi.”
Ale perspektywa wykracza poza skalę. Claude — ten sam model, którego ludzie używają do pisania maili, budowania aplikacji i analizowania finansów firmy — teraz pomaga ludzkości eksplorować inne światy. A przed nami misje Artemis (Księżyc), Europa, Tytan. Tam AI nie będzie luksusem. Będzie koniecznością.
Ludus Coriovalli — AI odszyfrowuje grę planszową sprzed 1500 lat
Na drugim końcu spektrum — nie w kosmosie, lecz w przeszłości — AI rozwiązało zagadkę, nad którą archeolodzy łamali sobie głowę od dziesięcioleci.
W kolekcji Het Romeins Museum w Heerlen znajduje się kamienny przedmiot pochodzący z Coriovallum — rzymskiego miasta. Na jego powierzchni wyryte są geometryczne linie tworzące wzór, który nie pasuje do żadnej znanej gry. Przez lata interpretowano go jako planszę do gry, ale bez znajomości zasad — które nigdy nie zostały spisane — hipoteza ta pozostawała nieweryfikowalna.
11 lutego 2026 roku w Cambridge University Press ukazała się praca łącząca dwie metody: analizę śladów zużycia i symulacje AI. Badacze najpierw przeanalizowali fizyczne ślady na kamieniu. Odkryli, że wzdłuż jednej z linii diagonalnych powierzchnia jest wyraźnie wygładzona — w sposób spójny z wieloletnim przesuwaniem kamiennych lub szklanych pionków. Mikroskopowa analiza potwierdziła: ziarno kamienia w strefach wzdłuż linii jest wyrównane i wygładzone bez mikropolerowania ani zarysowań — wzorzec zgodny z ścieraniem wywoływanym przez twardszy przedmiot.
Potem wkroczyło AI. Badacze użyli systemu Ludii — platformy do implementacji i analizy gier planszowych, stworzonej w ramach Digital Ludeme Project — do przeprowadzenia symulacji opartych na permutacjach zasad historycznych gier europejskich. Przeszukali bazę danych pod kątem gier rozgrywanych na planszach z dwudziestoma lub mniej polami, filtrując wyniki do gier udokumentowanych w Europie. Wyłoniły się dwa typy: gry blokujące (cel: zablokować ruch przeciwnika) i gry ustawieniowe (cel: ustawić trzy pionki w linii).
Z sześciu możliwych interpretacji geometrii linii na kamieniu, ze 130 konfiguracjami zasad, z tysiącem rund symulacji na każdą konfigurację — AI zidentyfikowało dziewięć konfiguracji, których wzorce użycia linii odpowiadały śladom zużycia na kamieniu. Wszystkie dziewięć to gry blokujące. Najbardziej prawdopodobna: gra czterech pionków przeciwko dwóm, z pionkami startującymi na planszy — wariant gier typu haretavl, znanych głównie ze Skandynawii i regionu bałtyckiego.
To osiągnięcie ilustruje coś, czego żaden benchmark nie zmierzy. AI rozwiązało problem, w którym nie istniały dane — zasady nigdy nie zostały spisane, nie zachowały się w żadnym tekście. Rozwiązanie wymagało połączenia analizy fizycznej (ślady zużycia na kamieniu) z symulacjami wieloagentowymi (dwa algorytmy grające przeciwko sobie tysiące razy). To nie jest kompresja wzorców z danych treningowych. To jest rekonstrukcja utraconej wiedzy poprzez symulację — coś, co zbliża się, choć jeszcze nie dorównuje, do tej abdukacji, o której pisze Zahavy.
I jest w tym coś poetyckiego. Gra, w którą grali ludzie półtora tysiąca lat temu na kamiennej planszy w rzymskim miasteczku — gra, której zasady zaginęły, bo nikt nie uznał za stosowne ich zapisać — została odtworzona przez sztuczną inteligencję.
VII. Wpływ na ludzi
Perspektywa Amodeia i Shumera
Dario Amodei, dyrektor generalny Anthropic, publicznie prognozuje, że AI wyeliminuje 50% biurowych stanowisk na poziomie wstępnym w ciągu jednego do pięciu lat. Shumer pisze, że wielu ludzi w branży uważa tę prognozę za konserwatywną.
„AI nie zastępuje jednej konkretnej umiejętności. Jest ogólnym substytutem pracy umysłowej. Poprawia się we wszystkim jednocześnie. (...) AI nie zostawia wygodnej luki, do której można wskoczyć. Na cokolwiek się przekwalifikujesz — ono też się w tym poprawia.”
To jest kluczowe zdanie. Każda poprzednia fala automatyzacji zostawiała lukę. Ale AI jest ogólne. Prawnicy, analitycy finansowi, pisarze, programiści, medycyna, obsługa klienta — wszyscy są na celowniku.
Hassabis jest ostrożniejszy. Zapytany wprost, czy zgadza się z prognozą Amodeia, odpowiada:
„Według mnie to potrwa znacznie dłużej. (...) Trzeba by rozwiązać problem spójności. Nie wystarczy, że system radzi sobie z 95% zadania. Musi radzić sobie z całością, żebyś mógł go puścić w świat i zapomnieć.”
Dziedziny „szachowe” kontra „pokerowe”
Nie wszystkie dziedziny są sobie równe — i to, co decyduje o podatności na automatyzację, nie jest trudność, lecz struktura problemu.
Dziedziny „szachowe” — deterministyczne, z pełną informacją, z obiektywną weryfikowalnością. AI dominuje tutaj. Kodowanie. Dowody formalne. Analiza danych. Matematyka.
Dziedziny „pokerowe” — z asymetrią informacji, ukrytymi stanami, wieloma agentami wzajemnie się modelującymi. Tu AI wciąż jest podatne na manipulację. Negocjacje. Prawo procesowe. Strategia biznesowa. Geopolityka.
Ale — i to jest kluczowe zastrzeżenie — granica między szachami a pokerem nie przebiega tam, gdzie myśli większość ludzi.
Pisanie kodu to szachy. Bycie doświadczonym inżynierem — rozumienie niejasnych wymagań, nawigowanie po polityce organizacyjnej, decydowanie, czego nie budować — to poker. Obserwator z zewnątrz widzi programistę i myśli „pisze kod, AI to zastąpi”. Ktoś, kto pracuje w branży, wie, że pisanie kodu to może 50% pracy — reszta to modelowanie świata pełnego ludzi z ukrytymi motywacjami.
To samo dotyczy prawa. Pisanie pism procesowych to szachy — i AI robi to coraz lepiej. Ale siedzenie naprzeciwko przeciwnika w sali sądowej, czytanie jego mowy ciała, wyczuwanie, kiedy blefuje, wiedząc, że on robi to samo z Tobą — to poker.
Ten podział — szachy kontra poker — rezonuje z czymś, o czym pisaliśmy obszerniej w poprzedniej serii o weryfikowalności AI. Kluczowym czynnikiem nie jest trudność zadania, lecz jego weryfikowalność. Tam, gdzie sukces da się jednoznacznie zmierzyć — czy odpowiedź matematyczna jest poprawna, czy kod się kompiluje, czy białko zostało złożone prawidłowo — AI osiąga wyniki na poziomie ludzkich ekspertów lub wyższe. Ale tam, gdzie „sukces" jest kwestią osądu — czy esej jest „dobry", czy strategia prawna jest „sprawiedliwa", czy lekcja była „wartościowa" — AI generuje coś, co wygląda jak sukces, ale czego nie da się algorytmicznie zweryfikować.
Rady na „najważniejszy rok kariery”
Shumer kończy swój esej konkretnymi radami:
Zacznij płacić za AI. Darmowe wersje ChatGPT czy Claude są o ponad rok za tym, co mają płacący użytkownicy. To jak ocenianie stanu smartfonów na podstawie telefonu z klapką. 20 dolarów miesięcznie — tyle kosztuje najlepszy korepetytor, analityk i asystent na świecie. I upewnij się, że używasz najlepszego dostępnego modelu w najlepszym agentowym środowisku.
Nie traktuj AI jak wyszukiwarki. To największy błąd, jaki popełnia większość ludzi. Zadają AI krótkie pytania i dziwią się, o co ten szum. Zamiast tego: daj AI prawdziwe zadanie z pracy. Jeśli jesteś prawnikiem — daj mu kontrakt i każ znaleźć każdą klauzulę, która może zaszkodzić klientowi. Jeśli jesteś finansistą — daj mu bałaganiarski arkusz kalkulacyjny i każ zbudować model. Jeśli coś nie wyjdzie za pierwszym razem — próbuj dalej, daj więcej kontekstu, podejdź inaczej. I zapamiętaj: jeśli AI choć trochę to potrafi dziś, za sześć miesięcy będzie to robić dużo lepiej.
Godzina dziennie eksperymentowania z AI — nie pasywnego czytania o nim, lecz używania. Każdego dnia spróbuj czegoś nowego, czegoś, czego nie próbowałeś, czegoś, co do czego nie jesteś pewien, czy AI da radę. Jeśli będziesz to robić przez sześć miesięcy, będziesz rozumiał, co nadchodzi, lepiej niż prawie wszyscy wokół Ciebie.
Bez ego. Główny partner dużej kancelarii prawnej — człowiek z dziesięcioleciami doświadczenia — spędza godziny dziennie z AI. Nie dlatego, że to zabawka. Dlatego, że to działa. Powiedział Shumerowi: „Co kilka miesięcy staje się znacznie bardziej zdolne w mojej pracy. Jeśli utrzyma tę trajektorię, spodziewam się, że będzie w stanie robić większość tego, co ja robię, zanim minie dużo czasu”. Ludzie, którzy najbardziej ucierpią, to ci, którzy odmówią zaangażowania — ci, którzy odrzucą to jako modę, poczują, że używanie AI umniejsza ich wiedzę specjalistyczną, założą, że ich dziedzina jest wyjątkowa i odporna.
Przemyśl, co mówisz dzieciom. Standardowy scenariusz — dobre oceny, dobra uczelnia, stabilna kariera — wskazuje prosto na stanowiska, które są najbardziej zagrożone. Shumer nie mówi, że edukacja nie ma znaczenia. Mówi, że najważniejszą rzeczą dla następnego pokolenia jest nauczenie się pracy z tymi narzędziami i podążanie za tym, co je naprawdę pasjonuje. Nikt nie wie, jak będzie wyglądał rynek pracy za dziesięć lat. Ale ludzie, którzy mają największe szanse, to ci, którzy są głęboko ciekawi, elastyczni i potrafią wykorzystać AI do robienia rzeczy, na których im naprawdę zależy.
Marzenia są bliżej
Bariera wejścia do tworzenia — aplikacji, książek, projektów, gier, filmów — praktycznie zniknęła.
„Jeśli kiedykolwiek chciałeś coś zbudować, ale nie miałeś umiejętności technicznych albo pieniędzy, żeby kogoś zatrudnić — ta bariera w dużej mierze zniknęła.”
Bariera wejścia do tworzenia — aplikacji, książek, projektów, gier, filmów — praktycznie zniknęła. To nie jest metafora. Hassabis sam mówi, że spędził Święta Bożego Narodzenia prototypując gry z pomocą Gemini 3 — i że vibe coding otworzy przestrzeń produkcyjną dla projektantów, artystów i twórców, którzy wcześniej potrzebowali dostępu do zespołów programistów.
Zakończenie
Trzy prawdy jednocześnie
Pisanie tego artykułu przypomina próbę sfotografowania wybuchającej supernowej. Zanim skończysz komponować kadr, obiekt wygląda już inaczej. Między momentem, gdy zacząłem zbierać materiały, a momentem, gdy kończę pisać, Gemini 3 Pro Deepthink osiągnął 84% na ARC-AGI 2 i nasycił benchmark.
Ale właśnie dlatego warto zakończyć nie prognozą, lecz syntezą — zbiorem trzech prawd, które są jednocześnie prawdziwe, nawet jeśli wydają się ze sobą sprzeczne.
Prawda pierwsza.
AI rozwija się szybciej, niż większość ludzi rozumie. Modele z lutego 2026 to inny świat niż rok temu. Shumer opisuje problem, odchodzi od komputera na cztery godziny — i wraca do gotowego produktu. Claude planuje trasę łazika na Marsie. AlphaEvolve poprawia algorytm Strassena z 1969 roku. AI odszyfrowuje zasady gry, w którą ludzie grali półtora tysiąca lat temu. Dane METR pokazują podwajanie złożoności zadań co cztery do siedmiu miesięcy — bez oznak spłaszczenia. Ludzie, którzy mówią „AI jest przesadzone”, najczęściej nie używali najnowszych modeli w środowisku agentowym. Ludzie, którzy ich używają, brzmią jak Shumer — jakby stracili rozum.
Prawda druga
AI nie rozumie jeszcze świata tak, jak rozumiemy go my Kaczka przechodzi przez ściany labiryntu. Duże modele językowe generują artefakty wyglądające ekspercko, ale nie przetrwałyby kontaktu z ekspertem. Brakuje abdukacji — zdolności do tworzenia nowych hipotez, konstruowania ram pojęciowych, których nie ma w danych treningowych. Brakuje modeli świata, ciągłego uczenia się, spójności, długoterminowego planowania.
Prawda trzecia
Droga do prawdziwego przełomu zaczyna się rysować. Genie 3 generuje interaktywne środowiska, nie filmy. Waymo World Model symuluje scenariusze, które nigdy nie zostały zarejestrowane przez kamery — tornado na autostradzie, słoń na jezdni. AlphaEvolve ewoluuje algorytmy w pętli, poprawiając najlepsze znane rozwiązania w 20% otwartych problemów matematycznych. Praca Zahavy’ego rysuje mapę drogową od kompresji danych, przez modele świata, do hipotetycznych eksperymentów i abdukacji. Hassabis mówi o konwergencji dużych modeli językowych, modeli świata i robotyki jako fundamentalnym planie Google DeepMind na AGI. To nie jest fantastyka naukowa — to mapa drogowa z zaznaczonymi przystankami. Niektóre z tych przystanków zostały już minięte.
O tak "Bariera wejścia do tworzenia — aplikacji, książek, projektów, gier, filmów — praktycznie zniknęła." - chociaż jedna rzecz:
Mamy odblokowane bariery tworzenia, natomiast kreatywność wciąż w ludziach IMHO!
Całość ostatecznie przekonuje i trwoży jednocześnie, choć próby uspokojenia jak najbardziej są widoczne.
Gdzieś mi brakuje jeszcze jednak bardzo istotnego elementu - potencjału zrozumienia. O ile "problem" dotyczy WSZYSTKICH, to zrozumienie większości mechanizmów tu naszkicowanych dostępnych poznawczo jest dla kilku procent ludzi. To mnie wręcz paraliżuje.
Potrzebujemy uproszczeń i mostów komunikacyjnych, żeby reszta nie została z tyłu. Teraz artykuł gra w szachy, gdy społeczeństwo jako całość gra w pokera.