
Weryfikowalność
#71

Cześć i czołem dobry człowieku! 👋
„AI zabije zawód prawnika”? Nie tak szybko. ⚖️
Zamiast masowego bezrobocia czeka nas ekonomia weryfikacji. W dzisiejszym odcinku zbadamy, dlaczego AI potrafi napisać apelację w 30 sekund, a potem skompromitować wyrok sędziego. Porozmawiamy o „poszarpanej granicy” i przyszłości specjalistów.
Dzięki, że jesteś z nami - Życzymy owocnej lektury :)
Weryfikowalność jako klucz do zrozumienia automatyzacji AI

Wizje masowego bezrobocia wśród wykwalifikowanych specjalistów powracają falami, za każdym razem obiecując, że tym razem „to już naprawdę koniec”. Jeszcze w 2016 roku Geoffrey Hinton – jeden z ojców głębokiego uczenia – ogłosił, że powinniśmy przestać szkolić radiologów, bo w ciągu pięciu lat algorytmy ich zastąpią. Dekadę później radiolodzy, prawnicy i nauczyciele wciąż są na swoich stanowiskach, a my po raz kolejny przekonujemy się o trafności słynnego bon motu, który chętnie przywołuje Andrzej Dragan, polski fizyk zajmujący się również sztuczną inteligencją: „Przewidywanie jest trudne, a szczególnie przewidywanie przyszłości” (Quo vaidis, 2025). W świecie AI to zdanie nabiera szczególnej wagi – pokazuje bowiem, że nasze intuicje dotyczące tego, co „łatwe” do zautomatyzowania, systematycznie nas zwodzą. Co zatem poszło nie tak z przepowiedniami?

Odpowiedź może tkwić w koncepcji, którą Andrej Karpathy – współzałożyciel OpenAI i były dyrektor ds. sztucznej inteligencji w Tesli – nazywa weryfikowalnością. To pojęcie wyjaśnia nie tylko dlaczego jedne zadania poddają się automatyzacji szybciej niż inne. Ma także potencjał wyjaśniający fakt, dlaczego postęp AI przypomina poszarpaną linię graniczną, a nie równomiernie przesuwającą się falę. Weryfikowalność to również klucz do zrozumienia, dlaczego te same modele językowe, które rozwiązują złożone problemy matematyczne, potrafią się pomylić licząc palce na obrazie.
Od Oprogramowania 1.0 do Oprogramowania 2.0
Żeby zrozumieć, dlaczego weryfikowalność ma znaczenie, trzeba najpierw uchwycić głęboką zmianę w sposobie tworzenia programów komputerowych. Karpathy wprowadza rozróżnienie między dwoma paradygmatami: Oprogramowaniem (Software) 1.0 i Oprogramowaniem 2.0.
W tradycyjnym paradygmacie – Oprogramowaniu 1.0 – programista pisze kod linia po linii, definiując dokładnie, co program ma robić na każdym etapie. Jeśli chcesz, żeby komputer obliczył sumę dwóch liczb, piszesz instrukcję dodawania. Jeśli chcesz, żeby posortował listę, implementujesz algorytm sortowania. Programista jest architektem rozwiązania, a zachowanie systemu jest deterministyczne i w pełni zrozumiałe dla swojego twórcy. Można powiedzieć, że w tym paradygmacie inteligencja systemu jest dokładnie równa inteligencji włożonej przez programistę – ani mniej, ani więcej.
W nowym paradygmacie – Oprogramowaniu 2.0 – programista nie pisze kodu w tradycyjnym sensie. Zamiast tego definiuje cel (funkcję celu, funkcję nagrody) i dostarcza dane. Sieć neuronowa sama „pisze” program, przeszukując przestrzeń możliwych konfiguracji wag metodą gradientową, aż znajdzie taką, która najlepiej realizuje zadany cel. To radykalna zmiana epistemologiczna: przejście od jawnej instrukcji do optymalizacji. Programista przestaje być architektem rozwiązania. Staje się raczej architektem procesu poszukiwania rozwiązania.
Różnicowanie tego rodzaju ma daleko idące konsekwencje. W Oprogramowaniu 1.0 programista musi rozumieć problem na tyle dobrze, żeby opisać rozwiązanie krok po kroku. W Oprogramowaniu 2.0 wystarczy, że potrafi rozpoznać dobre rozwiązanie, gdy je zobaczy. To przejście od „umiem to zrobić” do „umiem to ocenić” – i właśnie ta asymetria między generowaniem a weryfikacją może stać się kluczowa dla zrozumienia granic AI.
Gdyby w latach osiemdziesiątych XX wieku chcieć przewidzieć, które zawody zostaną zautomatyzowane przez komputery, najlepszym predyktorem byłoby pytanie: czy algorytm tego zadania jest stały? Czy przekształcasz informacje według rutynowych, łatwych do określenia reguł – jak maszynistka, księgowy czy ludzki kalkulator? To właśnie ta klasa zadań była podatna na automatyzację przez Oprogramowanie 1.0. Natomiast w erze Oprogramowania 2.0 najlepszym predyktorem jest coś innego: weryfikowalność.
Triada weryfikowalności
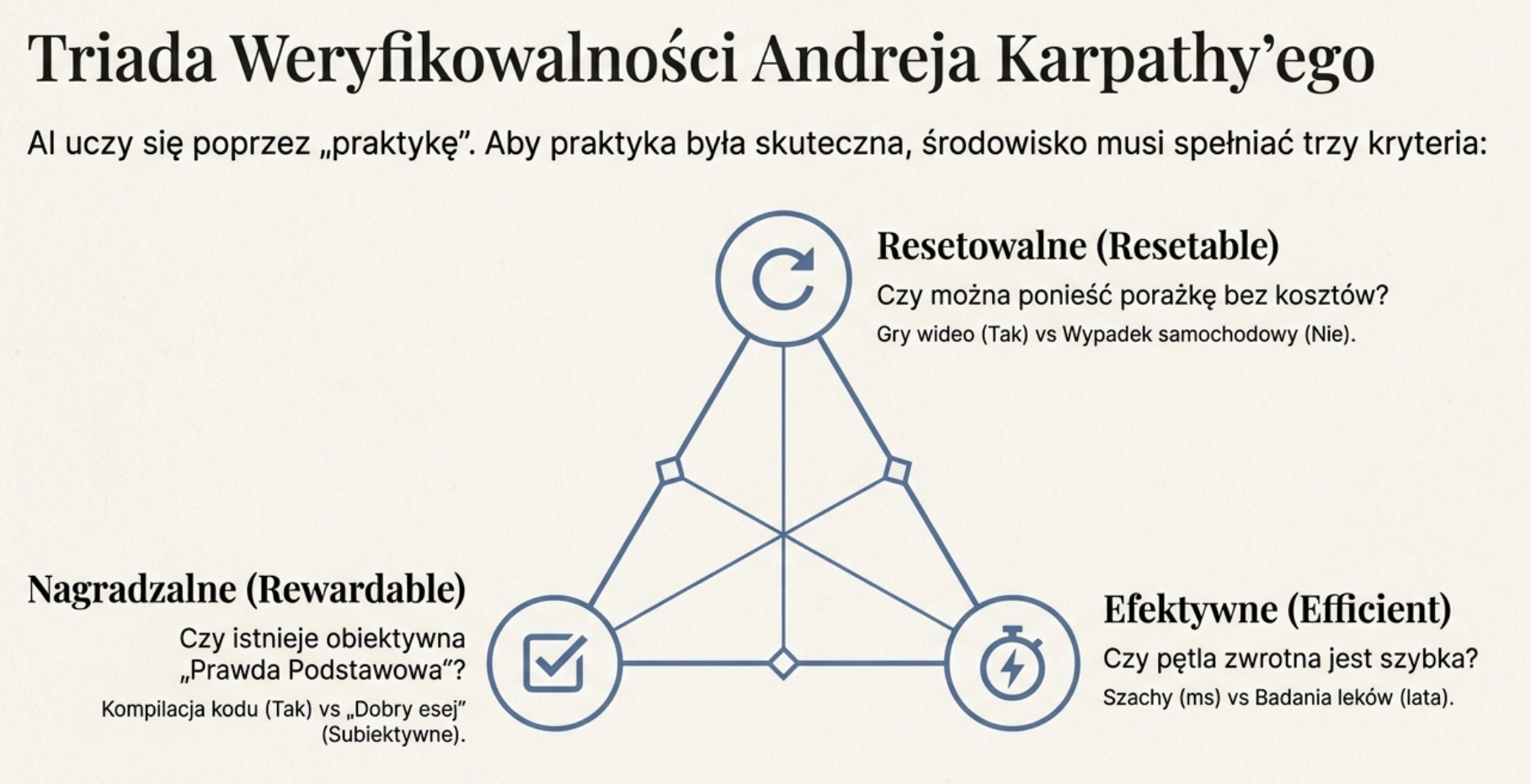
Karpathy argumentuje, że jeśli zadanie jest weryfikowalne, to jest optymalizowalne – bezpośrednio lub przez uczenie ze wzmocnieniem – a sieć neuronowa może zostać wytrenowana do jego doskonałego wykonywania. Chodzi o to, w jakim stopniu AI może „ćwiczyć” dane zadanie. Metafora ćwiczenia jest niezwykle trafna: tak jak pianista doskonali się przez tysiące godzin powtórzeń z natychmiastową informacją zwrotną (fałszywa nuta jest słyszalna od razu), tak AI doskonali się przez miliardy iteracji z automatycznym sygnałem nagrody.
Definiuje on weryfikowalne środowisko poprzez trzy rygorystyczne kryteria. Po pierwsze, środowisko musi być resetowalne: możesz rozpocząć nową próbę od zera, bez żadnych kosztów ani konsekwencji. Jeśli AI rozbije prawdziwy samochód, eksperyment się kończy – samochód jest zniszczony, ludzie mogą być ranni, konsekwencje prawne i finansowe są realne. Jeśli rozbije samochód w symulacji, środowisko resetuje się natychmiast. Automatyzacja wymaga możliwości porażki miliardy razy bez konsekwencji. To wyjaśnia, dlaczego AI osiąga nadludzkie wyniki w grach (szachy, Go, gry wideo) znacznie wcześniej niż w zadaniach fizycznych – gry są doskonale resetowalne, rzeczywistość nie.
Po drugie, środowisko musi być efektywne: pętla zwrotna między działaniem a oceną musi być krótka – milisekundy, nie miesiące. To pozwala AI szybko przemierzać przestrzeń poszukiwań możliwych rozwiązań. Rozważmy kontrast: AI grające w szachy otrzymuje informację o wyniku ruchu natychmiast. AI próbujące przewidzieć skuteczność leku musi czekać na wyniki badań klinicznych – lata, nie milisekundy. Im dłuższa pętla zwrotna, tym wolniejsze uczenie i tym trudniej o przełom.
Po trzecie, środowisko musi być nagradzalne: musi istnieć zautomatyzowany, jednoznaczny mechanizm punktowania każdej próby. To jest funkcja „prawdy podstawowej” – ground truth. W labiryncie nagrodą jest dotarcie do wyjścia. W kompilatorze kodu nagrodą jest udana kompilacja bez błędów. W grze w szachy nagrodą jest wygrana. Ale co jest nagrodą za „dobry esej”? Za „trafną diagnozę w niejednoznacznym przypadku”? Za „sprawiedliwy wyrok”? Im bardziej subiektywna ocena, tym słabszy sygnał nagrody i tym trudniej AI się uczyć.
Ten framework wyjaśnia nierównomierny rozkład sukcesów AI. Dlaczego AlphaGo pokonało Lee Sedola w 2016 roku? Ponieważ gra w Go jest doskonale resetowalna, efektywna i nagradzalna. AI mogło rozgrywać miliony partii samo ze sobą, generując własne weryfikowalne dane – bez potrzeby ludzkiego nadzoru czy kosztownych eksperymentów w rzeczywistości.
Przeciwstawmy to „negocjowaniu traktatu pokojowego” albo „pocieszaniu żałobnika”. Te zadania nie są resetowalne (masz jedną szansę, a porażka ma realne konsekwencje), nie są efektywne (skutki widoczne po latach lub dekadach), i nie są ściśle nagradzalne (sukces jest subiektywny – czy traktat był „dobry”? dla kogo?). Im dalej od triady weryfikowalności, tym bardziej AI musi polegać na „magii generalizacji” – na nadziei, że wzorce wyuczone gdzie indziej przeniosą się na nowe domeny.
Przejście od RLHF do RLVR
Implikacje tej teorii przekształcają technologiczną mapę rozwoju AI. W swoim podsumowaniu „2025 LLM Year in Review” Karpathy wskazuje na zmianę paradygmatu w metodologiach treningu – zmianę, która bezpośrednio wynika z ograniczeń weryfikowalności.
Historycznie duże modele językowe były trenowane przy użyciu RLHF – uczenia ze wzmocnieniem opartego na ludzkiej informacji zwrotnej. W tym podejściu ludzie oceniają odpowiedzi AI, a model uczy się preferować te, które ludzie lubili bardziej. To eleganckie rozwiązanie problemu braku automatycznej funkcji nagrody: skoro nie wiemy, jak algorytmicznie zdefiniować „dobrą odpowiedź”, niech ludzie będą funkcją nagrody.
Choć skuteczne, RLHF jest jednak ograniczone przez „wąskie gardło człowieka”. Po pierwsze, ludzie są powolni – mogą ocenić może kilkadziesiąt odpowiedzi na godzinę, podczas gdy AI może wygenerować miliony. Co czyni pętlę zwrotną nieefektywną. Po drugie, ludzie są niespójni – ten sam człowiek może ocenić tę samą odpowiedź różnie w zależności od nastroju, zmęczenia czy kontekstu. To z kolei czyni funkcję nagrody nierzetelną. Po trzecie, ludzie mogą być oszukiwani przez pewnie brzmiące, ale błędne odpowiedzi – to zjawisko nazywane „pochlebstwem” (sycophancy), gdzie AI uczy się mówić to, co ludzie chcą usłyszeć, zamiast tego, co jest prawdą.
Branża przechodzi teraz w kierunku RLVR – uczenia ze wzmocnieniem opartego na weryfikowalnych nagrodach. W tym podejściu AI jest trenowane na zadaniach, gdzie nagroda jest automatyczna. Zamiast pytać człowieka „czy ten kod Pythona jest dobry?”, system po prostu uruchamia kod. Jeśli kompiluje się i przechodzi testy jednostkowe, AI otrzymuje nagrodę. Jeśli zawodzi, otrzymuje karę. Żadnych subiektywnych ocen, żadnych niespójności, żadnego wąskiego gardła – tylko czysta, automatyczna informacja zwrotna.
Taka zmiana pozwala AI „myśleć” poprzez autokorektę. Generując „łańcuch myśli” i weryfikując własne kroki według twardej logiki, AI rozwija zdolności rozumowania, które wydają się odrębne od prostego dopasowywania wzorców. Modele trenowane przez RLVR wykazują zdolność do „zatrzymania się i przemyślenia” problemu – bo nauczyły się, że pośpieszne odpowiedzi często są błędne i prowadzą do kary.
Jednak RLVR jest możliwe tylko w domenach, które mają weryfikowalne nagrody – głównie matematyka, kodowanie i sztywne łamigłówki logiczne. Ogromna większość pracy zawodowej – prawo, medycyna, nauczanie – pozostaje “uparcie” poza domeną RLVR, uwięziona w świecie ludzkiej subiektywności. Co tworzy asymetrię: AI może ćwiczyć matematykę niemal w nieskończoność, ale nie może wyćwiczyć diagnozowania rzadkich chorób czy rozstrzygania sporów prawnych.
Poszarpana granica postępu
Profesor Ethan Mollick z Wharton School wprowadził termin „jagged frontier” – poszarpanej granicy – żeby opisać nierównomierny postęp zdolności AI. Ta metafora idealnie uzupełnia framework weryfikowalności Karpathy’ego i pomaga zrozumieć, dlaczego intuicje o „prostych” i „trudnych” zadaniach tak często zawodzą.
Wyobraź sobie mapę zadań, gdzie oś pozioma reprezentuje trudność (w ludzkim rozumieniu), a oś pionowa – zdolność AI. Tradycyjna automatyzacja sugerowałaby gładką linię: AI radzi sobie z prostymi zadaniami, a bardziej złożone wymagają człowieka. Rzeczywistość jest inna. Linia graniczna jest poszarpana: AI może doskonale rozwiązywać niektóre bardzo trudne zadania (złożone dowody matematyczne, pisanie skomplikowanego kodu), a jednocześnie zawodzić w pozornie prostych (zrozumienie sarkazmu, liczenie palców na obrazie, określenie czy w zdaniu „Anna powiedziała Marii, że ją kocha” – kogo kocha Anna).
Kluczem do zrozumienia tej poszarpanej granicy jest właśnie weryfikowalność. Zadania weryfikowalne postępują gwałtownie, potencjalnie przekraczając zdolności najlepszych ekspertów – matematyka, kod, wszystko, co przypomina łamigłówki z poprawnymi odpowiedziami. Wiele innych pozostaje w tyle: zadania kreatywne, strategiczne, wymagające połączenia wiedzy o świecie rzeczywistym, kontekstu i zdrowego rozsądku.
Poszarpana granica ma praktyczne konsekwencje dla profesjonalistów. Nie można zakładać, że AI poradzi sobie z „prostszą” częścią pracy, podczas gdy człowiek zajmie się „trudniejszą”. Granica nie przebiega wzdłuż intuicyjnej osi trudności. Prawnik może odkryć, że AI doskonale pisze skomplikowane pisma procesowe (weryfikowalne przez zgodność z procedurą), ale zawodzi przy prostym rozpoznaniu emocjonalnego stanu klienta. Lekarz może zobaczyć, że AI trafnie interpretuje złożone wyniki badań (weryfikowalne przez późniejszą biopsję), ale myli się oceniając, czy pacjent mówi prawdę o swoich objawach.
Stąd maksyma Karpathy’ego: „Oprogramowanie 1.0 łatwo automatyzuje to, co możesz określić. Oprogramowanie 2.0 łatwo automatyzuje to, co możesz zweryfikować.”
Gradient weryfikowalności i jego konsekwencje
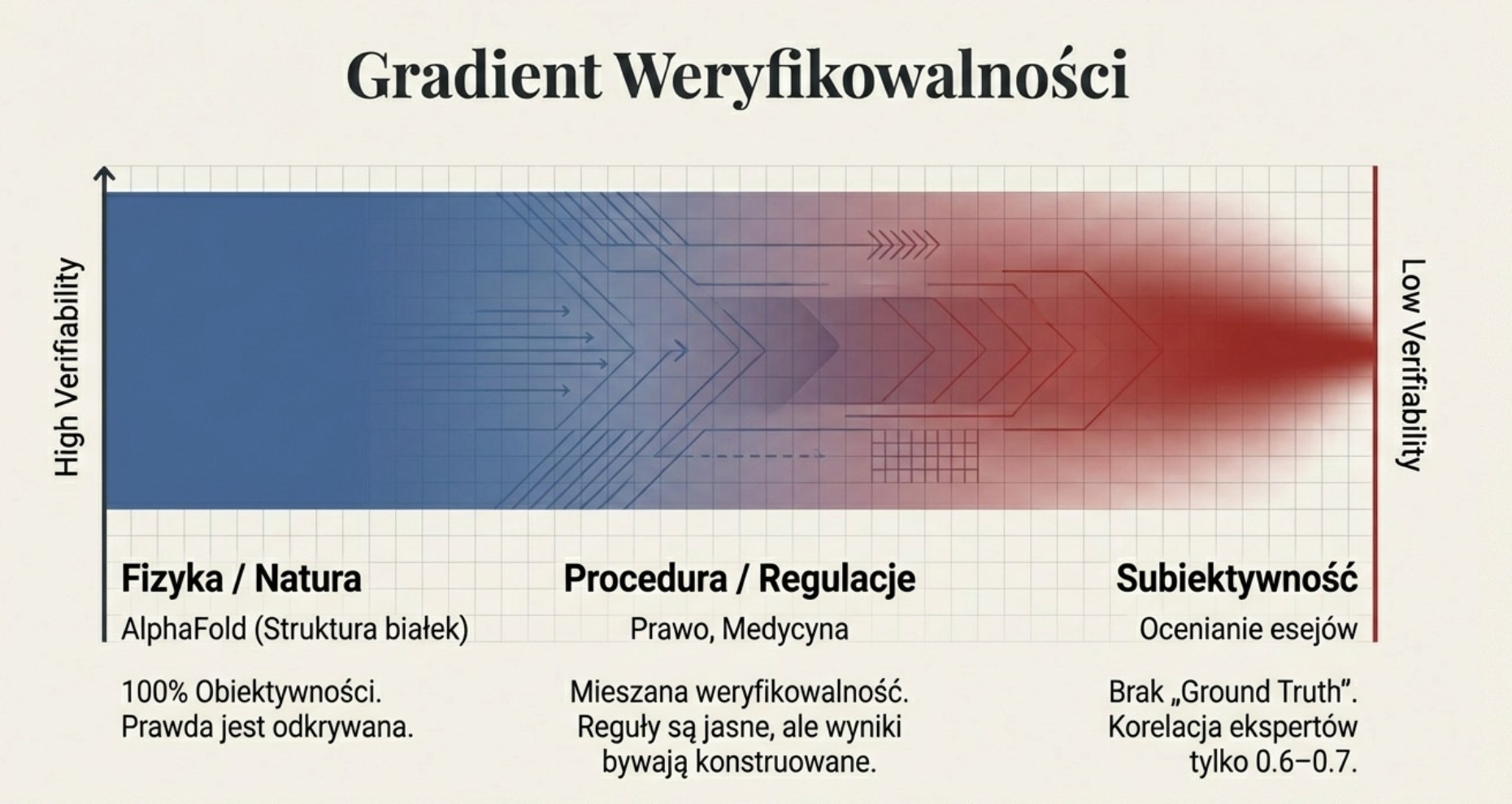
Kluczowe jest zrozumienie, że weryfikowalność nie jest kategorią binarną, lecz gradientem – spektrum rozciągającym się od deterministycznej fizyki składania białek po nieuchwytne tajemnice ludzkiego uczenia się. Pozycja zadania na tym spektrum determinuje nie tylko to, czy może być zautomatyzowane, ale również jak – jakie metody treningu są dostępne, jak szybko AI może się doskonalić, i gdzie leżą granice jego kompetencji.
Na jednym końcu spektrum znajduje się AlphaFold – system, który rozwiązał pięćdziesięcioletni problem biologii: przewidywanie struktury trójwymiarowej białka na podstawie sekwencji aminokwasowej. To doskonale weryfikowalna domena, rządzona prawami fizyki. Struktura białka albo odpowiada rzeczywistości (weryfikowanej przez krystalografię rentgenowską), albo nie. Nie ma miejsca na subiektywną interpretację, nie ma „częściowo poprawnych” odpowiedzi, nie ma debaty ekspertów o tym, jak białko „powinno” się składać. Fizyka jest arbitrem, a fizyka nie negocjuje.
Na drugim końcu spektrum znajduje się ocena eseju ucznia. Czy esej jest „dobry”? To zależy od kryteriów, które same są przedmiotem debaty. Czy liczy się oryginalność myśli, poprawność gramatyczna, znajomość materiału, umiejętność argumentacji? I kto ma rację, gdy dwóch nauczycieli oceni ten sam esej inaczej? Badania pokazują, że korelacja między ocenami różnych egzaminatorów tego samego eseju wynosi około 0.6–0.7 – daleko od doskonałej zgodności (Starch i Elliott, 1912– Reliability of the Grading of High School Work in English.). Jeśli ludzie nie potrafią się zgodzić co do „prawdy podstawowej”, jak ma się jej nauczyć AI?
Między tymi ekstremami rozciąga się cały świat zawodów i zadań. Prawo, medycyna i edukacja zajmują różne pozycje na tym spektrum – i właśnie ta pozycja determinuje, jak AI przekształca każdą z tych dziedzin. W prawie „prawda” jest najczęściej (tj. zależnie od kultury prawnej) konstruowana w toku procesu – zwycięża nie odpowiedź „obiektywnie poprawna”, lecz ta, która przekona sędziego lub ławę przysięgłych. W medycynie istnieje ostateczna weryfikacja (czy pacjent wyzdrowiał?), ale jest ona oddalona w czasie i zamazana przez niezliczone zmienne zakłócające. W edukacji weryfikacja jest najbardziej problematyczna – co tak naprawdę mierzymy, gdy wystawiamy ocenę?
Ekonomia weryfikacji

Analiza weryfikowalności prowadzi do głębszego wniosku o naturze pracy w epoce AI. Wchodzimy w erę, którą można nazwać „ekonomią weryfikacji”. Gdy koszt generowania inteligencji zbliża się do zera – bo generowanie tekstu, obrazów czy kodu przez AI jest niemal darmowe – wartość weryfikowania tej inteligencji rośnie nieproporcjonalnie.
O analogicznym zagadnieniu (co zaznaczał w ostatnich dniach także prof. Sankowski) pisaliśmy kilka miesięcy temu w kontekście paradoksu Jevonsa (zob. TUTAJ)




W pewnym sensie jest to odwrócenie tradycyjnej ekonomii wiedzy. Przez wieki rzadkim zasobem była zdolność do generowania: pisania, analizowania, diagnozowania, orzekania. Teraz generowanie staje się towarem – każdy może poprosić AI o napisanie pisma prawniczego, postawienie wstępnej diagnozy, stworzenie materiału edukacyjnego. Rzadkim zasobem staje się zdolność do weryfikacji: rozpoznanie, czy wygenerowany tekst jest prawniczo poprawny, czy diagnoza ma sens w kontekście konkretnego pacjenta, czy materiał edukacyjny rzeczywiście uczy.
Profesjonaliści, którzy odniosą sukces, nie będą tymi, którzy rywalizują z AI w generowaniu. Będą tymi, którzy opanują sztukę weryfikowalnej krytyki – umiejętność zakotwiczenia probabilistycznych wyników AI w rzeczywistości. To wymaga innych kompetencji niż tradycyjna ekspertyza: nie tylko wiedzy jak coś zrobić, ale przede wszystkim wiedzy jak rozpoznać, że zostało zrobione dobrze.
Jest to przekształcenie ról zawodowych. Nie chodzi o to, że AI zastępuje prawników, lekarzy czy nauczycieli. Chodzi o to, że przekształca ich w „głównych weryfikatorów” – profesjonalistów, których kluczową kompetencją staje się ocena, korekta i walidacja wyników generowanych przez maszyny. Prawnik przyszłości może spędzać mniej czasu na pisaniu pism, a więcej na krytycznej ocenie pism wygenerowanych przez AI. Lekarz może polegać na AI przy wstępnej analizie wyników, ale jego wartość dodana będzie w rozpoznaniu, kiedy AI się myli. Nauczyciel może delegować generowanie materiałów, ale nie może delegować oceny, czy uczeń naprawdę zrozumiał.
Struktura serii
Powyższa część teoretyczna stanowi fundament dla trzech analiz branżowych, które składają się na całą serię. Część I: Prawo zbada, jak brak weryfikowalnej „poprawnej odpowiedzi” w sporze sądowym zachowuje ludzką rolę nawet przy zerowym marginalnym koszcie generowania tekstów prawniczych – i jak charakter procesu sądowego tworzy sytuację, gdzie „prawda” jest konstruowana, nie odkrywana. Część II: Medycyna skontrastuje sukces AI w weryfikowalnych domenach „biologii cyfrowej” (jak AlphaFold) z wyzwaniami „analogowego bałaganu” klinicznej praktyki, gdzie diagnoza jest hipotezą, nie faktem, a weryfikacja przychodzi zbyt późno, żeby służyć za sygnał treningowy. Część III: Edukacja zmierzy się z paradoksem „AI jako tutor” – systemu, który oferuje spersonalizowaną instrukcję, ale walczy z „luką walidacyjną” w ocenianiu, gdzie mierzymy nie to, co chcemy mierzyć, a to, co potrafimy mierzyć.
We wszystkich trzech przypadkach weryfikowalność okaże się kluczem do zrozumienia, dlaczego katastroficzne przepowiednie o śmierci zawodów pozostają niezmiennie fałszywe – i jak naprawdę wygląda przyszłość pracy profesjonalnej w epoce algorytmów. Nie jest to przyszłość, w której ludzie są zastąpieni. Jest to przyszłość, w której ludzie są przemieszczeni – z pozycji generatorów na pozycję weryfikatorów, z producentów wiedzy na strażników jej jakości.
Dlaczego AI (prawdopodobnie) nie zabije wszystkich prawników

Adwokat sądowy w barze w Soho
Grudzień 2025, półmrok eleganckiego londyńskiego baru dla członków. Sean Thomas z The Spectator spotyka się z anonimowym adwokatem sądowym (barrister) – nazwijmy go James – który chce powiedzieć coś, za co znienawidzi go cała profesja. James opowiada o eksperymencie: wzięli prawdziwą, skomplikowaną apelację cywilną, nad którą pracował półtora dnia, i przekazali ją modelowi Grok Heavy. Trzydzieści sekund. Wynik spektakularny, oszałamiający, lepszy niż jego własny. „To był poziom naprawdę wielkiego radcy królewskiego (King’s Counsel). Najlepszy możliwy dokument prawny. A wszystko w kilka sekund, za grosze. Jak którykolwiek z nas może z tym konkurować? Nie możemy.”
James jest pewien diagnozy: prawo jest skończone. Najpierw praca papierkowa, potem pisanie, cytowanie, argumentacja. „Prawnicy procesowi są oczywiście skazani. AI będzie obsługiwać najbardziej złożone sprawy spadkowe i nieruchomościowe w sekundy. Najbardziej skomplikowaną ludzką umiejętnością będzie” – śmieje się smutno – „skanowanie i digitalizacja papierowych dokumentów.” Na pytanie o halucynacje i potrzebę ludzkiej twarzy w sądzie odpowiada machnięciem ręki: „Tymczasowe błędy i sentymentalne preferencje. Argument ekonomiczny jest przytłaczający.”
Artykuł Thomasa pod tytułem „AI Will Kill All the Lawyers” niemal natychmiast sprowokował gwałtowne reakcje z obu stron barykady. Stał się manifestem techno-apokaliptycznego spojrzenia na przyszłość profesji prawniczej – wizji, w której ekonomia zerowego kosztu krańcowego generowania dokumentów prawnych zmiatała każdego: od aplikantów po sędziów.
Kontrola dostępu i samoobrona korporacji zawodowej
Odpowiedź nadeszła szybko. Luiza Jarovsky, prawniczka i doktor nauk prawnych, współzałożycielka AI, Tech & Privacy Academy, której biuletyn (newsletter) o zarządzaniu AI (AI governance) czyta niemal 90 tysięcy subskrybentów, przedstawiła radykalnie odmienną diagnozę.
„Jako prawniczka, pozwólcie, że powiem wam główny powód, dla którego AI prawdopodobnie NIE zabije wszystkich prawników i dlaczego prawo jest właściwie jednym z najbardziej ‘bezpiecznych przed AI’ zawodów dzisiaj: profesja prawnicza jest bardzo dobra w ochronie samej siebie.“
Luiza Jarovsky
Jej argument opiera się na obserwacji, że prawo jest zbudowane wokół idei kompetencji, autorytetu, wiarygodności i kontroli dostępu (gatekeeping). Tak funkcjonowało przez stulecia. Jeśli systemy AI staną się bardzo dobre w generowaniu strukturalnie złożonych i prawniczo poprawnych dokumentów, zasady procedury prawnej zostaną zmienione, żeby zapewnić, że ludzki prawnik jest zawsze zaangażowany w sprawę i że każdy prawnie istotny dokument jest przejrzany oraz podpisany przez człowieka. Izby adwokackie na całym świecie prawdopodobnie stworzą nowe regulacje reprezentacji prawnej – proceduralne i behawioralne – tak, że ludzki prawnik zawsze będzie niezbędny.
„Nie widzę, żeby to się zmieniło w ciągu najbliższych 15-20 lat” – konkluduje Jarovsky. „Po tym czasie prawnicy prawdopodobnie znajdą nowy sposób na kontrolę dostępu do zawodu.”
Wzmocnienie, nie eliminacja?
Komentarze pod postem Jarovsky ujawniły trzecią perspektywę – być może najbardziej zniuansowaną. Jeden z komentujących napisał:
„Wierzę, że potencjał AI to automatyzacja rutynowych zadań takich jak pisanie projektów, badania prawne i przegląd umów. Nie sądzę, że AI kiedykolwiek osiągnie punkt, w którym będzie mogła odtworzyć ludzkie umiejętności takie jak budowanie relacji, negocjacje i strukturyzowanie transakcji – tam, gdzie faktycznie leży zestaw umiejętności prawnika. To właśnie umiejętności wymagające intuicji i doświadczenia. AI nie zabije prawników, ale raczej stworzy nowe umiejętności do rozwinięcia, takie jak inżynieria podpowiedzi (prompt engineering) i zarządzanie przepływem pracy. AI będzie wzmacniać prawników, żeby lepiej pracowali, a nie ich zastępować.”
Ta perspektywa „centaura” – człowieka i maszyny pracujących w symbiozie – wydaje się najbardziej zbliżona do rzeczywistości, którą obserwujemy w kancelariach. Niemniej sama w sobie nie odpowiada na pytanie: dlaczego akurat prawo miałoby być odporne na automatyzację, skoro inne profesje wymagające lat nauki i doświadczenia – od tłumaczy po programistów – doświadczają głębokiej transformacji?
Paradoks Sandie Peggie, czyli kiedy AI zawodzi w sądzie

Ironia chciała, że zaledwie kilka dni przed publikacją artykułu w Spectatorze, rzeczywistość dostarczyła kontrapunktu dla narracji o AI triumfującej w prawie. W grudniu 2025 roku sędzia Alexander Kemp opublikował ponad 300-stronicowy wyrok w sprawie Sandie Peggie przeciwko NHS Fife – głośnej sprawie dotyczącej pielęgniarki, która sprzeciwiła się dzieleniu damskiej przebieralni z transpłciową lekarką.
Wyrok szybko stał się przedmiotem skandalu. Maya Forstater, aktywistka i świadek w sprawie, odkryła, że cytat przypisany jej własnemu orzeczeniu trybunalskiemu sprzed lat był całkowicie zmyślony – takie słowa nigdy nie padły w żadnym dokumencie sądowym. „Znam ten wyrok na wylot” – powiedziała dziennikarzom. „Te słowa tam nie występują”. Wkrótce odkryto drugi sfabrykowany cytat. Potem trzeci. Wyrok zawierał też amerykańską pisownię wyrazów („victimization” zamiast brytyjskiego „victimisation”), błędną nazwę organizacji interweniującej w sprawie oraz przekłamane dane ze szwedzkiego badania naukowego.
Dwanaście poprawek do wyroku zostało wprowadzonych w ciągu dwóch tygodni od publikacji. Sprawa trafiła do parlamentu szkockiego, gdzie poseł Murdo Fraser zażądał pilnego wyjaśnienia, czy sędzia korzystał z AI przy pisaniu orzeczenia. Biuro Sądownictwa (Judicial Office) odmówiło komentarza, ale wytyczne sądowe z października 2025 roku wyraźnie ostrzegają, że narzędzia AI mogą „halucynować”, w tym „wymyślać fikcyjne sprawy, cytaty i cytowania”.
Oto paradoks: w tym samym miesiącu, w którym anonimowy adwokat sądowy ogłaszał śmierć zawodu prawniczego, sędzia – człowiek mający być ostatecznym weryfikatorem – najwyraźniej użył AI w sposób, który skompromitował cały wyrok. JK Rowling, publicznie wspierająca Peggie, nazwała zachowanie sędziego „absolutnie skandalicznym”.
Weryfikowalność jako klucz do rozwiązania paradoksu

Jak pogodzić te sprzeczne obserwacje? Z jednej strony AI potrafi wygenerować „najlepszy możliwy dokument prawny” w trzydzieści sekund. Z drugiej – ta sama technologia, użyta bez nadzoru, produkuje sfabrykowane cytaty, które kompromitują sądownictwo.
Albowiem odpowiedź leży w koncepcji weryfikowalności. Zadanie „napisz apelację” jest weryfikowalne w ograniczonym sensie: można sprawdzić, czy dokument ma poprawną strukturę, czy cytuje istniejące przepisy, czy argumentacja jest logicznie spójna. Ale zadanie „rozstrzygnij, kto ma rację w sporze między pielęgniarką a lekarką w kontekście zmieniających się norm społecznych” nie jest weryfikowalne w tym samym sensie – nie istnieje algorytmiczna funkcja nagrody, która mogłaby ocenić „poprawność” takiego rozstrzygnięcia.
I tutaj tkwi sedno problemu z apokaliptycznymi przepowiedniami o końcu zawodu prawniczego. Prawo nie jest dziedziną weryfikowalną w sensie, który umożliwia pełną automatyzację. Owszem, AI może generować dokumenty prawne – i robi to coraz lepiej. Natomiast generowanie dokumentu to nie to samo, co rozstrzyganie sprawy. A rozstrzyganie sprawy to nie to samo, co wymierzanie sprawiedliwości.
Adwokat James z artykułu w Spectatorze ma częściowo rację: AI rzeczywiście może napisać apelację „na poziomie wielkiego radcy królewskiego”. Ale Luiza Jarovsky też ma rację: profesja prawnicza nie pozwoli się łatwo zastąpić. Problem polega na tym, że żadne z tych stanowisk nie dotyka sedna sprawy. Pytanie nie brzmi „czy AI potrafi pisać dokumenty prawne” ani „czy prawnicy zdołają się obronić regulacjami”. Pytanie brzmi: co w pracy prawniczej jest weryfikowalne – a co wymyka się weryfikacji?
Analiza prawa przez pryzmat triady weryfikowalności Karpathy’ego ujawnia bowiem obraz zawodu, który balansuje na granicy między tym, co algorytmicznie mierzalne, a tym, co nieuchwytnie ludzkie. I właśnie ta granica określa, które zadania prawnicze są podatne na automatyzację – a które pozostaną domeną ludzi, nawet gdy (jeśli?) koszt generowania inteligencji spadnie do zera.
Varia. Matematyczne przełomy

Świat matematyki przechodzi właśnie trzęsienie ziemi. Z jednej strony mamy Terence’a Tao, legendę dyscypliny, ogłaszającego sukces modelu GPT-5.2-Pro w problemach Erdosa. Z drugiej – Bartosza Naskręckiego, współtwórcę ekstremalnie trudnego testu FrontierMath, który przyznaje wprost: nowe modele to coś więcej niż tylko sprawne kalkulatory.
Koniec statycznej publikacji
Punktem wyjścia jest niedawne, autonomiczne rozwiązanie przez AI problemu Erdosa nr 728 (dotyczącego rozkładu współczynników dwumianowych), który pozostawał otwarty od 1975 roku. Terence Tao zauważa jednak, że najciekawszy nie jest sam wynik, ale proces. AI w połączeniu z systemami formalnymi (jak Aristotle) potrafi błyskawicznie generować, weryfikować i – co kluczowe – redagować dowody. Tao wieszczy koniec ery, w której artykuł naukowy jest martwym, statycznym tekstem. Zmierzamy w stronę dynamicznych dokumentów, które AI może w locie dostosowywać do poziomu wiedzy czytelnika, zachowując przy tym stuprocentową poprawność logiczną.
Armia krasnoludków OpenAI
Jeszcze mocniej sytuację komentuje Bartosz Naskręcki. Odnosząc się do możliwości modelu GPT-5.2 Pro, stwierdza półżartem: “Albo OpenAI zatrudniło zespół krasnoludków i topowych matematyków pracujących 24/7, albo ten model faktycznie stał się tak dobry”.
Naskręcki zauważa, że trudno znaleźć teraz nietrywialny problem, którego AI nie byłoby w stanie rozwiązać po 1-2 godzinach interakcji. Pada nawet odważne stwierdzenie: “Osobliwość jest blisko”.
Nowa rola matematyka
Obaj badacze są zgodni, że rola człowieka w matematyce ulegnie zmianie, ale nie zniknie. Naskręcki przewiduje przesunięcie punktu ciężkości z “niskopoziomowej” dłubaniny nad technicznymi detalami w stronę wysokopoziomowego projektowania teorii. – “Myślę, że ludzie tacy jak Grothendieck byliby zachwyceni” – pisze Naskręcki, przywołując postać jednego z największych wizjonerów matematyki XX wieku. Grothendieck był “architektem teorii”, który szukał głębokich powiązań między działami matematyki, a nie tylko rozwiązań pojedynczych zagadek. Dzięki AI, matematycy będą mogli skupić się na takich właśnie “konstelacjach twierdzeń”, zostawiając czarną robotę agentom AI.
Cyfrowa Biblioteka Wszechwiedzy
Naskręcki pokusił się również o konkretną estymację tempa auto-formalizacji (czyli przepisywania matematyki na język zrozumiały i weryfikowalny dla komputerów):
5-10 lat
Przy obecnym tempie rozwoju modeli, powinniśmy zobaczyć sformalizowanie 60-80% krótszych prac matematycznych (do 15 stron). To będzie moment, w którym AI realnie wpłynie na większość nauk ścisłych.
15-25 lat
Przy zaangażowaniu ok. 10 000 matematyków i sporych zasobach obliczeniowych, możemy osiągnąć pokrycie rzędu 99%.
Efekt? Powstanie w pełni sprawdzona, cyfrowa baza wiedzy matematycznej, którą można przeszukiwać i aplikować niemal natychmiastowo. Zbliżamy się do momentu, w którym bariera wejścia w skomplikowaną matematykę drastycznie spadnie, a “układanie puzzli”, jak Naskręcki nazywa rozwiązywanie problemów, wejdzie na zupełnie nowy poziom.